PROJECT: SaveIt
1. Overview
This document outlines the contributions that Tan Zheng Wei has made to the SaveIt project.
SaveIt is targetted at programmer, and aims to help the user store and keep track of problems and solutions that they encounter. The application is meant to replace traditional use of bookmarks on browsers, and is customized especially for programmers, to make it easier for them to search for previously found solutions online. SaveIt is a desktop application that uses the Command Line Interface (CLI) as a mode to interact with it.
SaveIt is a project that is built over the course of CS2103T with a group of five members including myself.
2. Summary of contributions
-
Major enhancement: Suggestion Logic Subcomponent
-
What it does: This is a component of the codebase that allows the application to make suggestions to the user as they type.
-
Justification: This assists the user to type in commands, by automatically suggesting some possible values that the user might want to enter, it allows the user to complete the command much faster and with less effort.
-
Highlights: The architecture is built in a way that allows easy additions of other types of suggestions by future developers.
-
-
Other enhancements:
-
Code contributed: [Functional code]
-
Other contributions:
-
Project management:
-
Manage milestones and issues on the repository
-
-
Testing
-
Documentation:
-
Community:
-
3. Contributions to the User Guide
_Given below are sections I contributed to the User Guide. They showcase my ability to write documentation targeting end-users. |
3.1. Locating issues by statement: (f)find
Finds issues whose statement contain any of the given search queries.
Format: find [KEYWORDS…]
|
Examples:
|
3.2. Locating issues by tags: (ft)findtag
Finds issues that contain the tags entered in the search queries.
|
Examples:
|
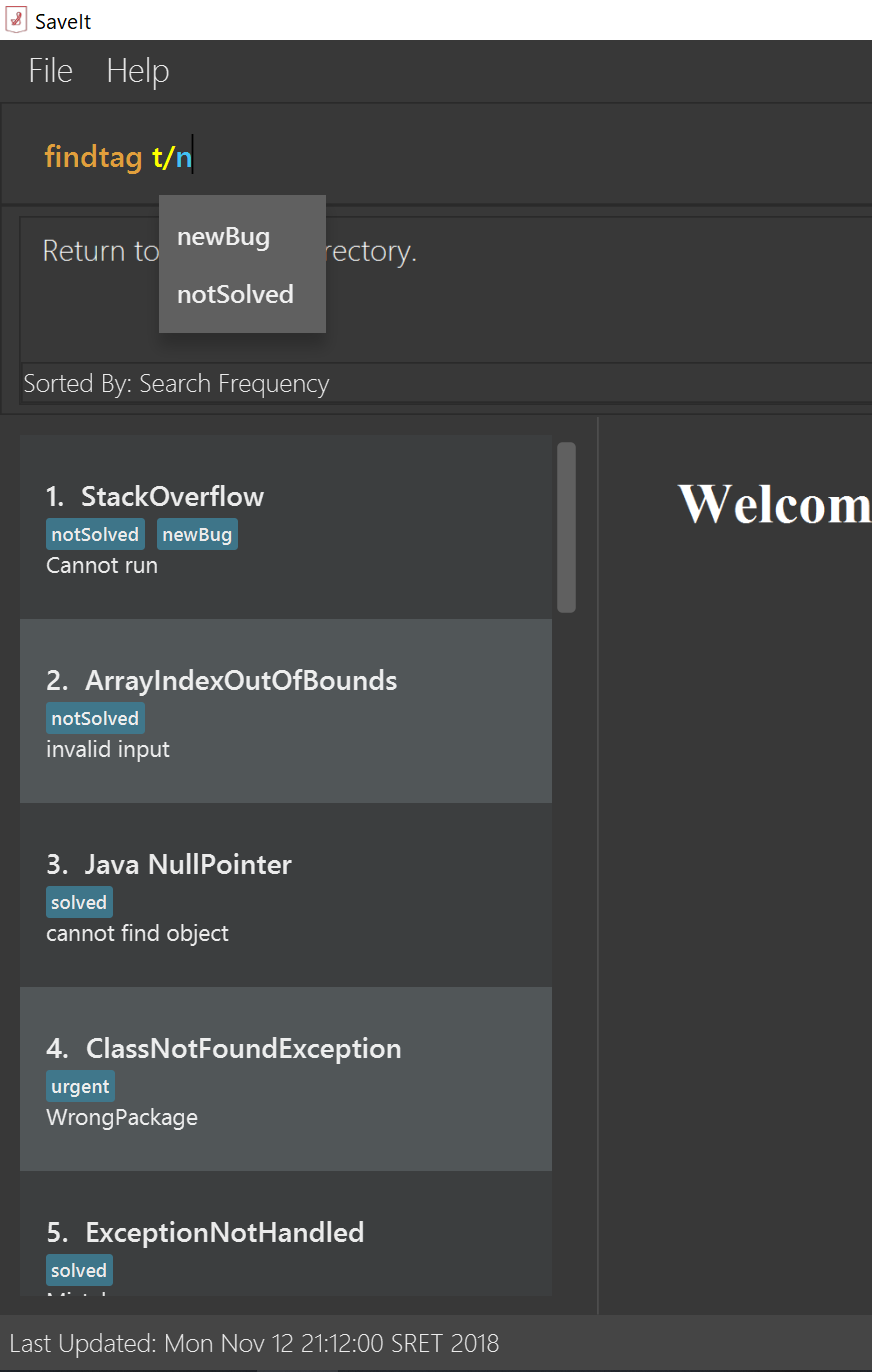
3.3. Autosuggesting existing tags in findByTag command
To prevent the user from creating many similar tags / duplicates, whenever the user creates a record with a tag, or modifies a record’s tag, the application searches for similar tags in the system and prompts the user with a list of similar tags.
Example:
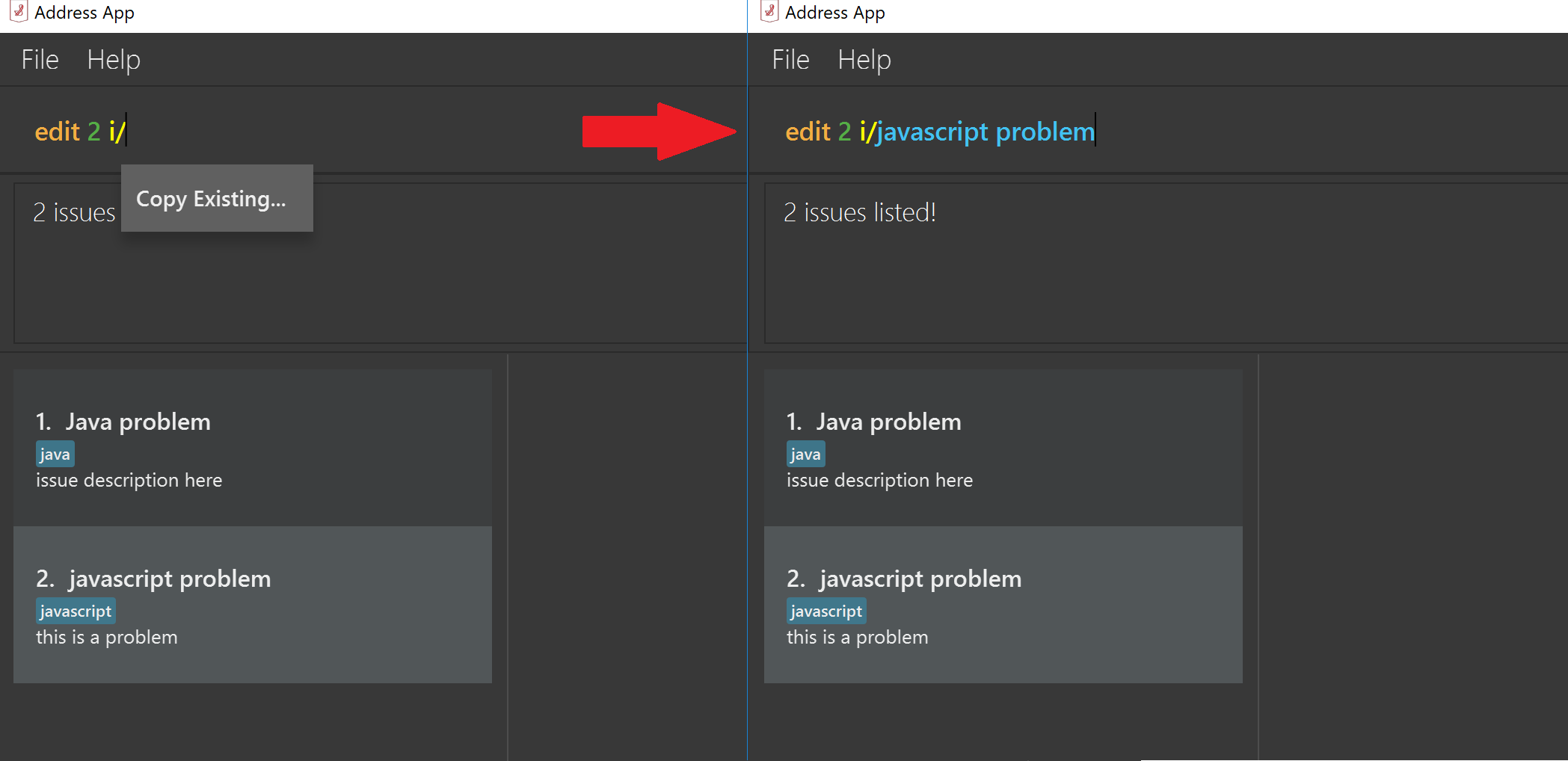
3.4. Suggesting to copy existing values
When editing fields in an issue (e.g. Editing an issue statement), if only slight modifications are required, the user will have to copy paste the existing issue statement and modify it, or type it out again. To make things more convenient, after the application prompts the user if they want to copy the existing value onto the command line.
Example:
4. Contributions to the Developer Guide
_Given below are sections I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
4.1. Logic component
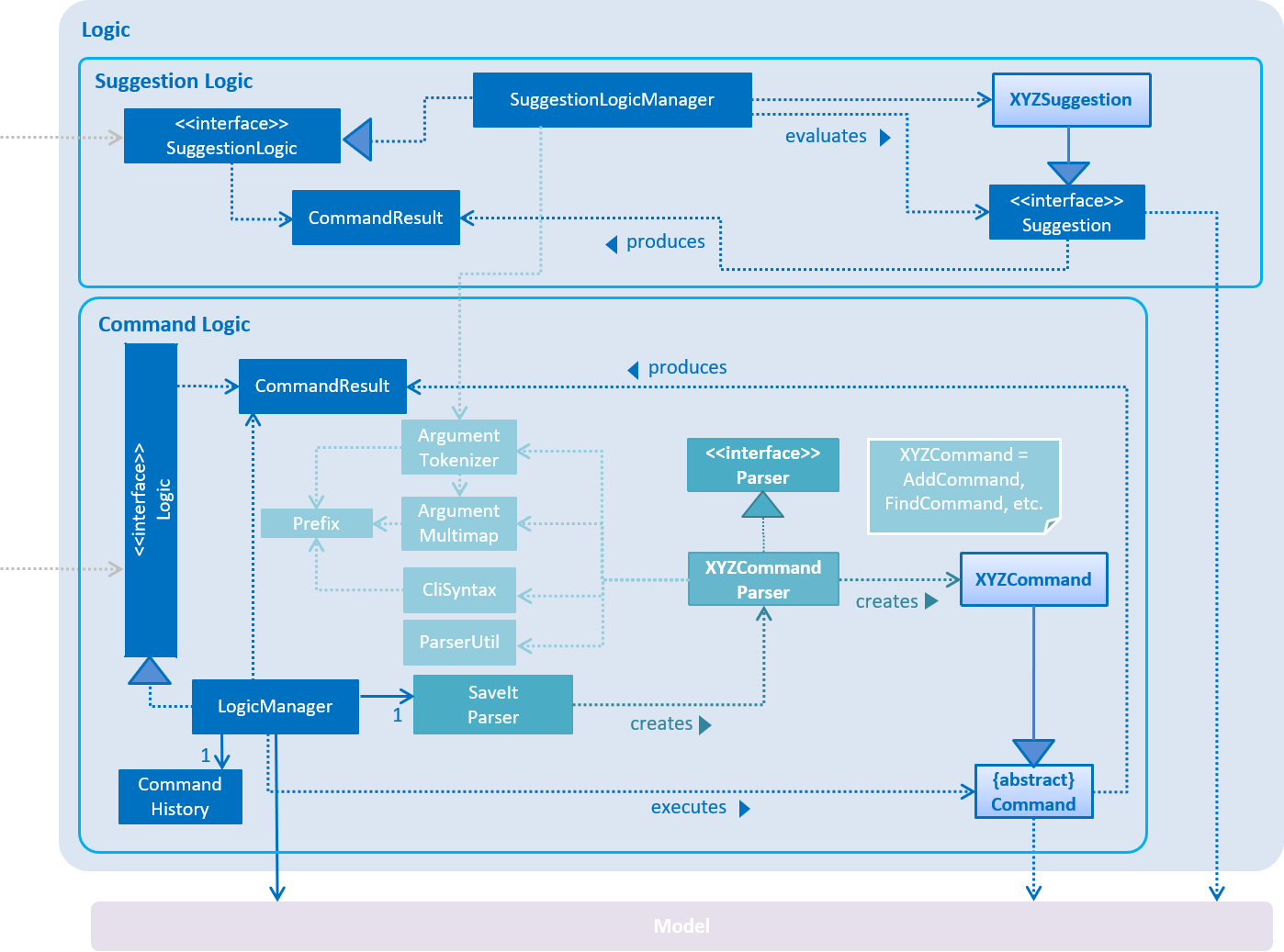
The Logic Component can be split into two subcomponents:
1. Command Logic Subcomponent
The command logic subcomponent encapsulates the execution of all commands. Each command is represented its own class (e.g. FindCommand.java, AddCommand.java) which all inherit from an abstract Command.java class.
API :
Logic.java
-
Logicuses theSaveItParserclass to parse the user command. -
This results in a
Commandobject which is executed by theLogicManager. -
The command execution can affect the
Model(e.g. adding a statement) and/or raise events. -
The result of the command execution is encapsulated as a
CommandResultobject which is passed back to theUi.
2. Suggestion Logic Subcomponent
The suggestion logic subcomponent encapsulates the evaluation of user inputs as it is keyed into the command line, differing from the command logic in that command logic is only executed upon entering the command, whereas suggestion logic is called whenever the user input changes (without the need to enter).
API :
SuggestionLogic.java
-
SuggestionLogicparses user inputs whenever it changes. -
This determines which
Suggestionobject is created by theSuggestionLogicManager. -
The evaluation of the
Suggestionobject reads data from theModel(e.g. finds a specificIssue). -
The result of the evaluation is encapsulated as a
SuggestionResultobject which is passed back to theUi.
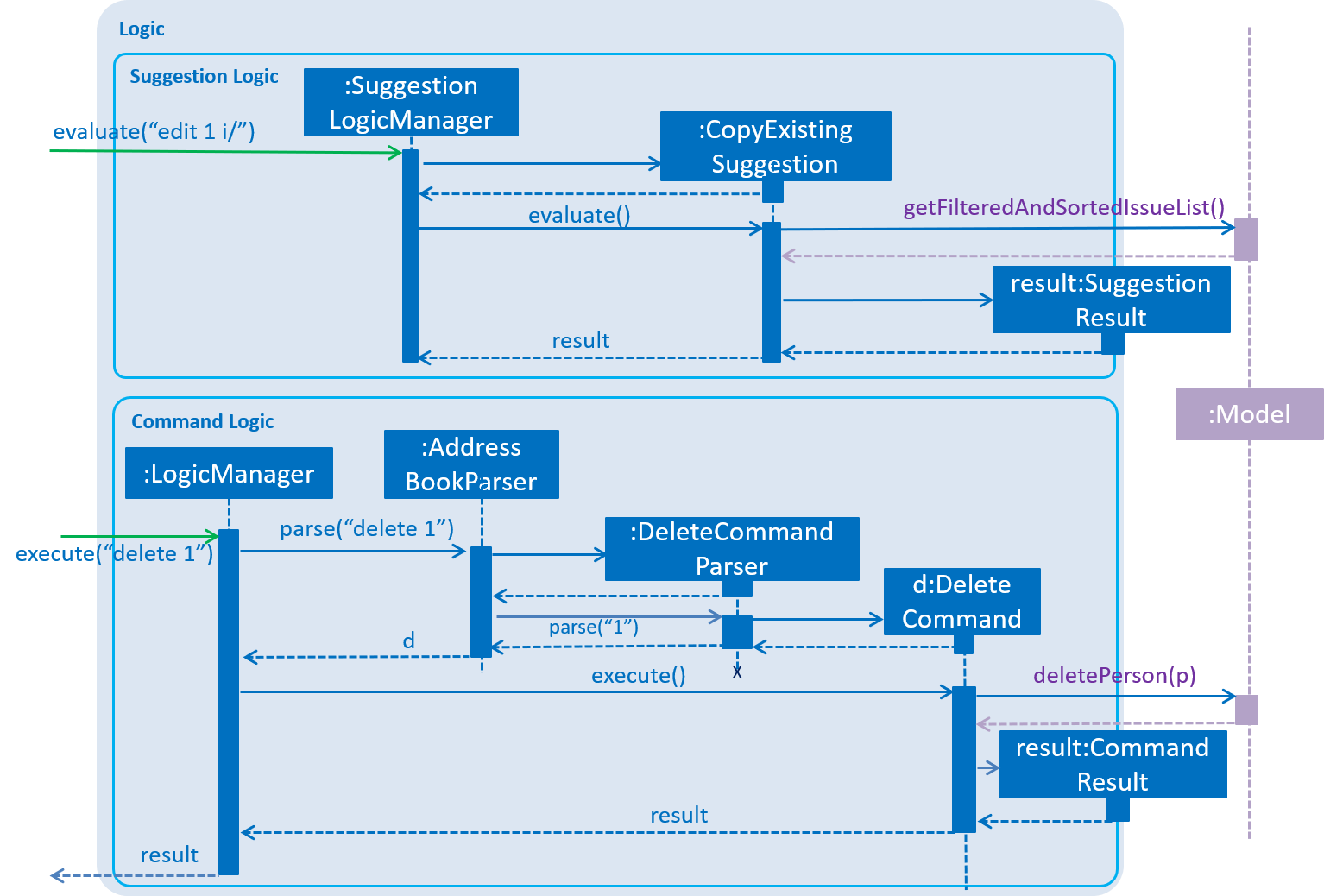
Given below is the Sequence Diagram for interactions within the Logic component when an API call is made. The Sequence Diagram is split into two branches of logic:
-
Command logic: Shows an example command execution of the
delete 1Command, which calls theDeleteCommand. -
Suggestion logic: Shows an example suggestion evaluation of the user input
edit 1 i/, which calls theCopyExistingSuggestion.
4.1.1. Design Consideration
Aspect 1: Architecture Design of the Suggestion Logic subcomponent
The architecture behind the Suggestion Logic subcomponent is designed by mimicking the original Logic component that handles the command logic. This is because the required implementation behind both is actually similar, needing to access both the Ui and the Model components. Hence, the SuggestionLogic and Suggestion are built similar to the original Logic component which has the corresponding classes Logic and Command that serves as interfaces to the Ui and Model components respectively. However, the internal implementation of the internal classes of the Suggesetion Logic subcomponent is different (i.e. Parser).
-
Alternative 1 (current choice): Create parser methods all within
SuggestionLogicManagerthat parse the user input directly - first parsing them based the commands (handled inSuggestionLogicManager#parseUserInput) and subsequently parsing based on thePrefixthat the text cursor is at.-
Pros: Keeps the code DRY.
-
Cons: Deviates from the original internal structure of the Command Logic subcomponent.
-
-
Alternative 2: Create parser classes for each command (e.g.
EditSuggestionParser) that handles the further parsing of thePrefixand creates the relevantSuggestionobject.-
Pros: Code is more modularized since the parsing is now handled by classes.
-
Cons: Code is repeated in each
SuggestionParserclass.
-
We use the first alternative as it best handles the issue of having duplicate logic. The internal parsing of the user inputs for suggestions differs from the Command Logic in that, Command Logic only has one level of parsing (parsing commands), whereas Suggestion Logic requires two levels (parsing commands and parsing prefixes). In order to ensure the same way of handling the same prefix in different commands (e.g. findtag t/ and edit 1 t/), methods are created to do so (e.g. SuggestionLogicManager#handleTagNameSuggestion). This keeps the code DRY and reduces repeats logic in the code.
Further abstractions can be made to this in the future as more Suggestion(s) added, by moving the suggestion handlers (SuggestionLogicManager#handleTagNameSuggestion) into a new Suggestion class (instead of an interface) that the specific XYZSuggestion(s) inherit from.
Aspect 2: Deciding on how to parse the user input
We have two options to parse the user input and find the prefixes and their values.
-
Alternative 1 (current choice): Use the existing
ArgumentTokenizerandArgumentMultimapto parse the user input-
Pros: The logic for separating the prefixes in
ArgumentTokenizerand storing them inArgumentMultimapis similar to what we need to parse our user input. By reusing the code, it prevents us from needing to rewrite code with duplicated logic elsewhere in our code base, which keeps our code DRY. -
Cons:
ArgumentTokenizerandArgumentMultimapis also used by the command logic subcomponent, by reusing this code in the suggestion logic subcomponent, it increases the coupling between the implementation of the two subcomponents which can result in new issues arising (aspects 3 and 4).
-
-
Alternative 2: Parse the input by using a separate piece of code (duplicated logic from the
ArgumentTokenizerandArgumentMultimap). Slight modifications will need to be made to the duplicated logic due to differences in implementation.-
Pros: Reduces the coupling between the two command and suggestion logic subcomponents. Although the logic behind the implementation will be similar to
ArgumentTokenizer, having it as a duplicate piece of code means that any changes will not affect and cause bugs in the other subcomponent. -
Cons: Having it duplicated logic might affect future development, especially when this duplicated logic needs to be modified, then the implementation for both pieces of code will have to be modified as well. If not documented properly, this could cause bugs if only one piece of code was modified.
-
Aspect 3: Data structure of Prefix
The original implementation of Prefix only stored the value of the prefix string (e.g. /t or /i), however since the implementation of the suggestion logic subcomponent uses ArgumentMultimap, it requires that the position of the Prefix in the user input string be known as well.
-
Alternative 1 (current choice): Store an additional field
positioninPrefix-
Pros: Since the prefix and its location are related, this keeps all the information pertaining to the prefix encapsulated in a single class, which helps with the modularity of the code.
-
Cons: The command logic subcomponent does not require the
positionfield inPrefix, which results in it being unused. This might be confusing for future developers. This also resulted in having another aspect to consider later on (aspect 4).
-
-
Alternative 2: Move the implementation and checks for the prefix position out of
Prefix-
Pros: This does not affect the code implemented in the Command logic subcomponent, and we will have less to fix.
-
Cons: Related pieces of code will be separated (i.e. since the position is stored separately, it is not properly encapsulated).
-
Aspect 4: Distinguishing each Prefix in ArgumentMultimap
The original hashcode used by Prefix only hashes the prefix string, as such, adding a position field will not make a difference since two same prefixes with different positions (e.g. /t … /t) will still hash to the same key. The previous implementation handles this by having the value in the HashMap within ArgumentMultimap store a List<String> which will append all values with the same prefix.
-
Alternative 1 (current choice): Set the hashcode of
Prefixto use both the prefix string and the position.-
Pros: The prefixes now hash differently if they have the same prefix string but different position, this allows us to have finer control needed for the Suggestion logic subcomponent when handling the prefixes in
ArgumentMultimap. -
Cons: The Command logic subcomponent does not make use of the
positionfield. As such, when attempting to extract out the values of eachPrefixat theParser, it cannot find the values as they are now hashed with thepositionas this is unknown to theParser(an indirect result of the coupling due to the chosen implementation in aspect 2).
-
-
Alternative 2: Use the original implementation
-
Pros: Code does not affect the Command logic subcomponent, which already takes up a significant portion of the code base, hence less changes are needed.
-
Cons: The code and logic are not be well encapsulated (for the
Prefix) and we will have repeated logic in the codebase.
-
We eventually chose Alternative 1 as it provides a better structure and encapsulation for our code overall. We also came up with a workaround for Alternative 1’s cons, by modifying the method ArgumentMultimap#getValue.