By: Team T12-4 Since: Sep 2018 Licence: MIT
- 1. Introduction
- 2. Setting up
- 3. Design
- 4. Implementation
- 4.1. Add feature
- 4.2. Sort feature
- 4.3. Undo/Redo feature
- 4.4. Confirmation Check
- 4.5. Logging
- 4.6. Configuration
- 4.7. Directory Level Model
- 4.8. UI Enhancement
- 4.9. Edit Feature
- 4.10. Retrieve Feature
- 4.11. Set Primary Feature
- 4.12. Reset Primary Feature
- 4.13. Refactor Tag Feature
- 4.14. Add tag Feature
- 4.15. Suggestion Feature
- 4.16. Command Highlight
- 5. Documentation
- 6. Testing
- 7. Dev Ops
- Appendix A: Suggested Programming Tasks to Get Started
- Appendix B: Product Scope
- Appendix C: User Stories
- Appendix D: Use Cases
- Appendix E: Non Functional Requirements
- Appendix F: Glossary
- Appendix G: Product Survey
- Appendix H: Instructions for Manual Testing
1. Introduction
This Developer Guide is written by the SaveIt team for the benefits of future developers and maintainers of the application.
-
Setup: The steps you need in order to set up your development environment for the application, as well as any prerequisites required by your system.
-
Design: Information on the underlying structure of the code, and how the logic of each model / component interact with each other through Unified Model Diagrams (UMLs).
-
Implementation: Contains a detailed explanation on how our core features implemented, and any considerations made behind the implementation.
-
Documentation: A general guide of the documentation process of the application.
-
Testing: Documentation for the coverage tests of the application and how to set up your testing environment.
-
Dev Ops: The general processes used during development phase, and documentation on how to set it up.
SaveIt is an open-source project, should any developers be interested, see Contact Us page for more information.
2. Setting up
This section provides the prerequisites and steps to set up development environment. The way to verify the set up and essential configurations are also included.
2.1. Prerequisites
-
JDK
9or laterJDK 10on Windows will fail to run tests in headless mode due to a JavaFX bug. Windows developers are highly recommended to use JDK9. -
IntelliJ IDE
IntelliJ by default has Gradle and JavaFx plugins installed.
Do not disable them. If you have disabled them, go toFile>Settings>Pluginsto re-enable them.
2.2. Setting up the project in your computer
-
Fork this repo, and clone the fork to your computer
-
Open IntelliJ (if you are not in the welcome screen, click
File>Close Projectto close the existing project dialog first) -
Set up the correct JDK version for Gradle
-
Click
Configure>Project Defaults>Project Structure -
Click
New…and find the directory of the JDK
-
-
Click
Import Project -
Locate the
build.gradlefile and select it. ClickOK -
Click
Open as Project -
Click
OKto accept the default settings -
Open a console and run the command
gradlew processResources(Mac/Linux:./gradlew processResources). It should finish with theBUILD SUCCESSFULmessage.
This will generate all resources required by the application and tests.
2.3. Verifying the setup
-
Run the
seedu.saveit.MainAppand try a few commands -
Run the tests to ensure they all pass.
2.4. Configurations to do before writing code
This section provides suggested configurations to check before start coding, including coding style set up, documentation update, as well as Continuous Integration set up.
2.4.1. Configuring the coding style
This project follows oss-generic coding standards. IntelliJ’s default style is mostly compliant with ours but it uses a different import order from ours. To rectify:
-
Go to
File>Settings…(Windows/Linux), orIntelliJ IDEA>Preferences…(macOS) -
Select
Editor>Code Style>Java -
Click on the
Importstab to set the order-
For
Class count to use import with '*'andNames count to use static import with '*': Set to999to prevent IntelliJ from contracting the import statements -
For
Import Layout: The order isimport static all other imports,import java.*,import javax.*,import org.*,import com.* `, `import all other imports. Add a<blank line>between eachimport
-
Optionally, you can follow the UsingCheckstyle.adoc document to configure Intellij to check style-compliance as you write code.
2.4.2. Updating documentation to match your fork
After forking the repo, the documentation will still have the SE-EDU branding and refer to the CS2103-AY1819S1-T12-4/main repo.
If you plan to develop this fork as a separate product (i.e. instead of contributing to CS2103-AY1819S1-T12-4/main), you should do the following:
-
Configure the site-wide documentation settings in
build.gradle, such as thesite-name, to suit your own project. -
Replace the URL in the attribute
repoURLinDeveloperGuide.adocandUserGuide.adocwith the URL of your fork.
2.4.3. Setting up CI
Set up Travis to perform Continuous Integration (CI) for your fork. See UsingTravis.adoc to learn how to set it up.
After setting up Travis, you can optionally set up coverage reporting for your team fork (see UsingCoveralls.adoc).
| Coverage reporting could be useful for a team repository that hosts the final version but it is not that useful for your personal fork. |
Optionally, you can set up AppVeyor as a second CI (see UsingAppVeyor.adoc).
| Having both Travis and AppVeyor ensures your App works on both Unix-based platforms and Windows-based platforms (Travis is Unix-based and AppVeyor is Windows-based) |
2.4.4. Getting started with coding
When you are ready to start coding,
-
Get some sense of the overall design by reading Section 3.1, “Architecture”.
-
Take a look at Appendix A, Suggested Programming Tasks to Get Started.
3. Design
This section provides the overview of this application, including the design of architecture, UI, logic, model, storage and common classes. Diagrams are also provided for the better understanding.
3.1. Architecture
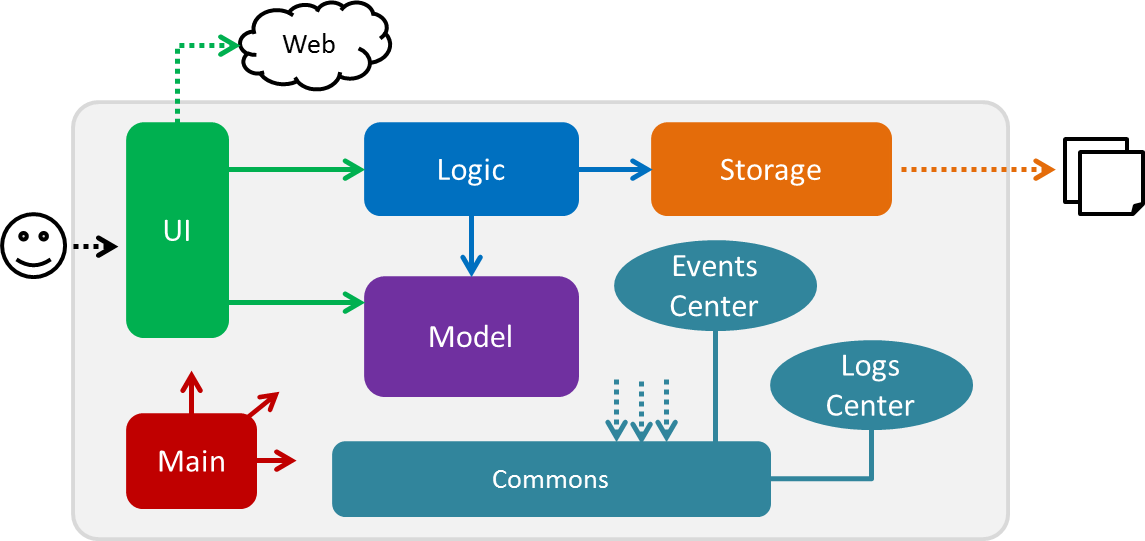
The Architecture Diagram given above explains the high-level design of the App. Given below is a quick overview of each component.
The .pptx files used to create diagrams in this document can be found in the diagrams folder. To update a diagram, modify the diagram in the pptx file, select the objects of the diagram, and choose Save as picture.
|
Main has only one class called MainApp. It is responsible for:
-
At app launch: Initializing the components in the correct sequence, and connects them up with each other.
-
At shut down: Shutting down the components and invokes cleanup method where necessary.
Commons represents a collection of classes used by multiple other components. Two of those classes play important roles at the architecture level:
-
EventsCenter: This class (written using Google’s Event Bus library) is used by components to communicate with other components using events (i.e. a form of Event Driven design) -
LogsCenter: This class is used by other classes to write log messages to the App’s log file.
The rest of the App consists of four components:
Each of the four components:
-
Defines its API in an
interfacewith the same name as the Component. -
Exposes its functionality using a
{Component Name}Managerclass.
For example, the Logic component (see the class diagram given below) defines its API in the Logic.java interface and exposes its functionality using the LogicManager.java class.
Events-Driven nature of the design.
The Sequence Diagram below shows how the components interact for the scenario where the user issues the command delete 1.
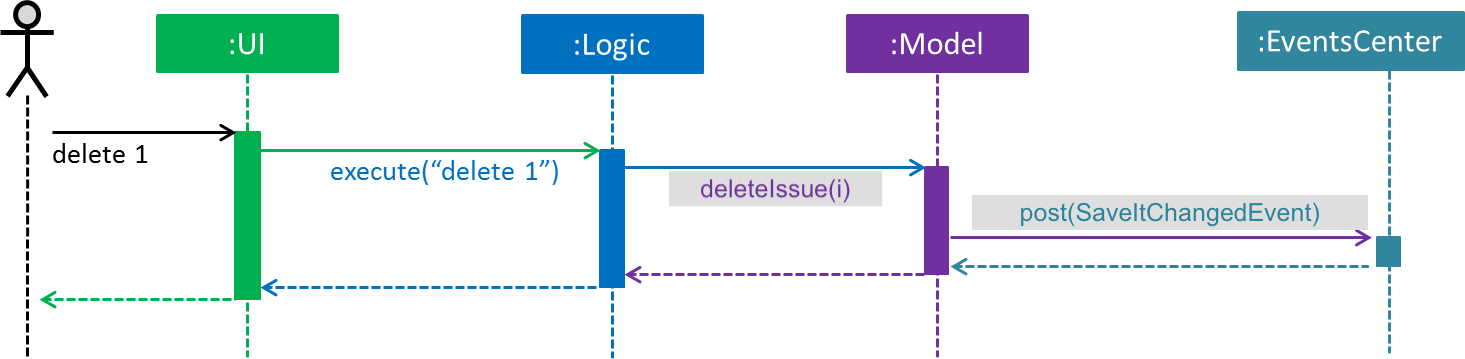
delete 1 command (part 1)
Note how Model simply raises a SaveItChangedEvent when the SaveIt data is changed, instead of asking the Storage to save the updates to the hard disk.
|
The diagram below shows how the EventsCenter reacts to that event, which eventually results in the updates being saved to the hard disk and the status bar of the UI being updated to reflect the 'Last Updated' time.
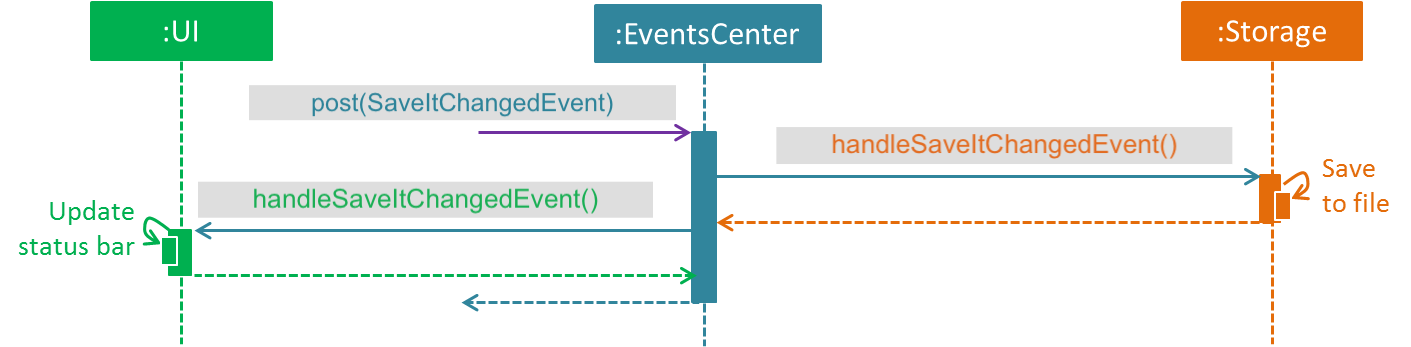
delete 1 command (part 2)
Note how event is propagated through the EventsCenter to the Storage and UI without Model having to be coupled to either of them. This is an example of how this Event Driven approach helps us reduce direct coupling between components.
|
The sections below give more details of each component.
3.2. UI component
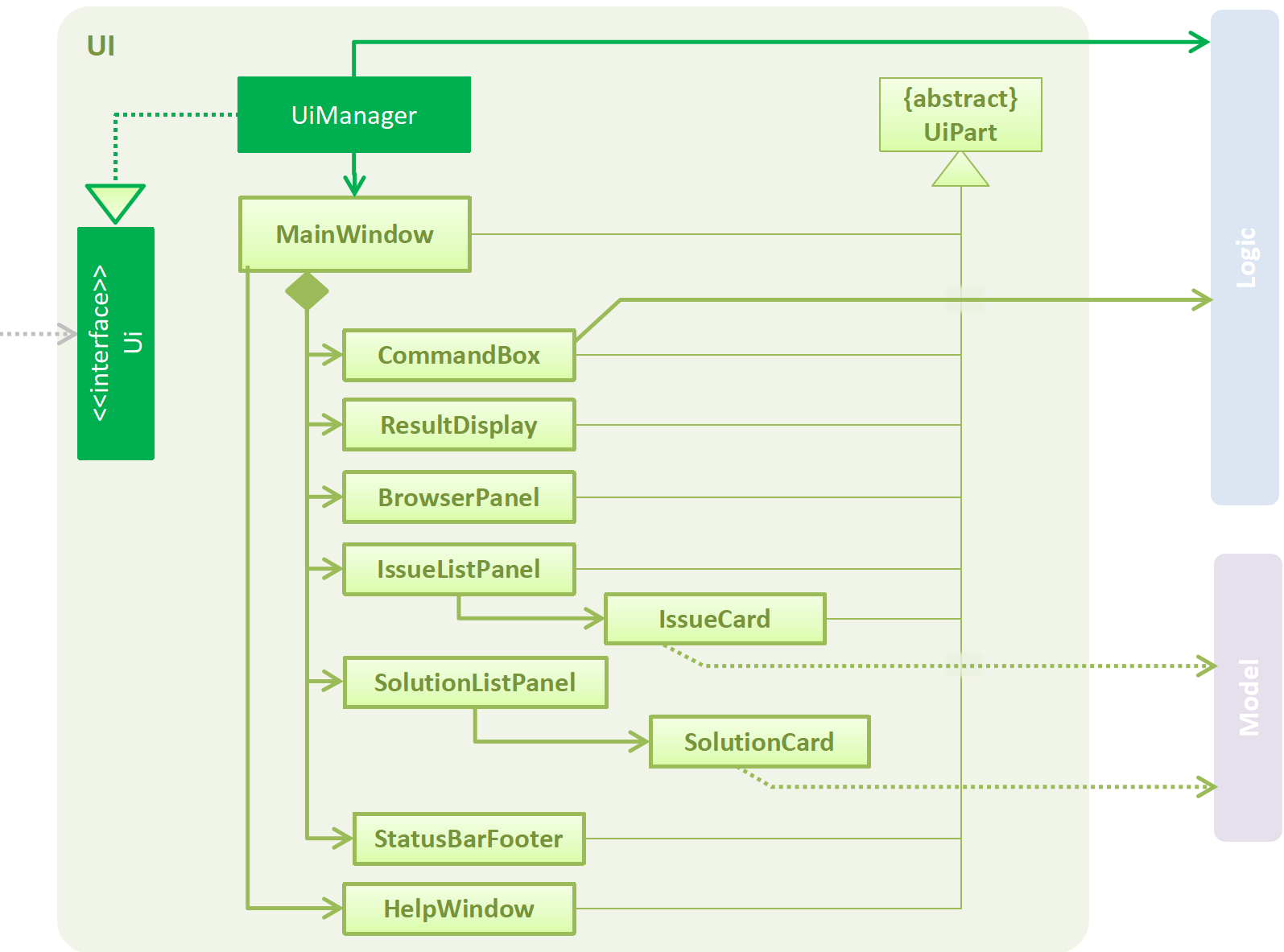
The figure above shows the breakdown of the smaller components involved in the UI Component. The UI Component is the interface (abstraction barrier) between the user and the underlying components - Model and Logic.
API : Ui.java
The UI consists of a MainWindow that is made up of parts e.g.CommandBox, ResultDisplay, PersonListPanel, StatusBarFooter, BrowserPanel etc. All these, including the MainWindow, inherit from the abstract UiPart class.
The UI component uses JavaFx UI framework. The layout of these UI parts are defined in matching .fxml files that are in the src/main/resources/view folder. For example, the layout of the MainWindow is specified in MainWindow.fxml
The UI component,
-
Executes user commands using the
Logiccomponent. -
Binds itself to some data in the
Modelso that the UI can auto-update when data in theModelchange. -
Responds to events raised from various parts of the App and updates the UI accordingly.
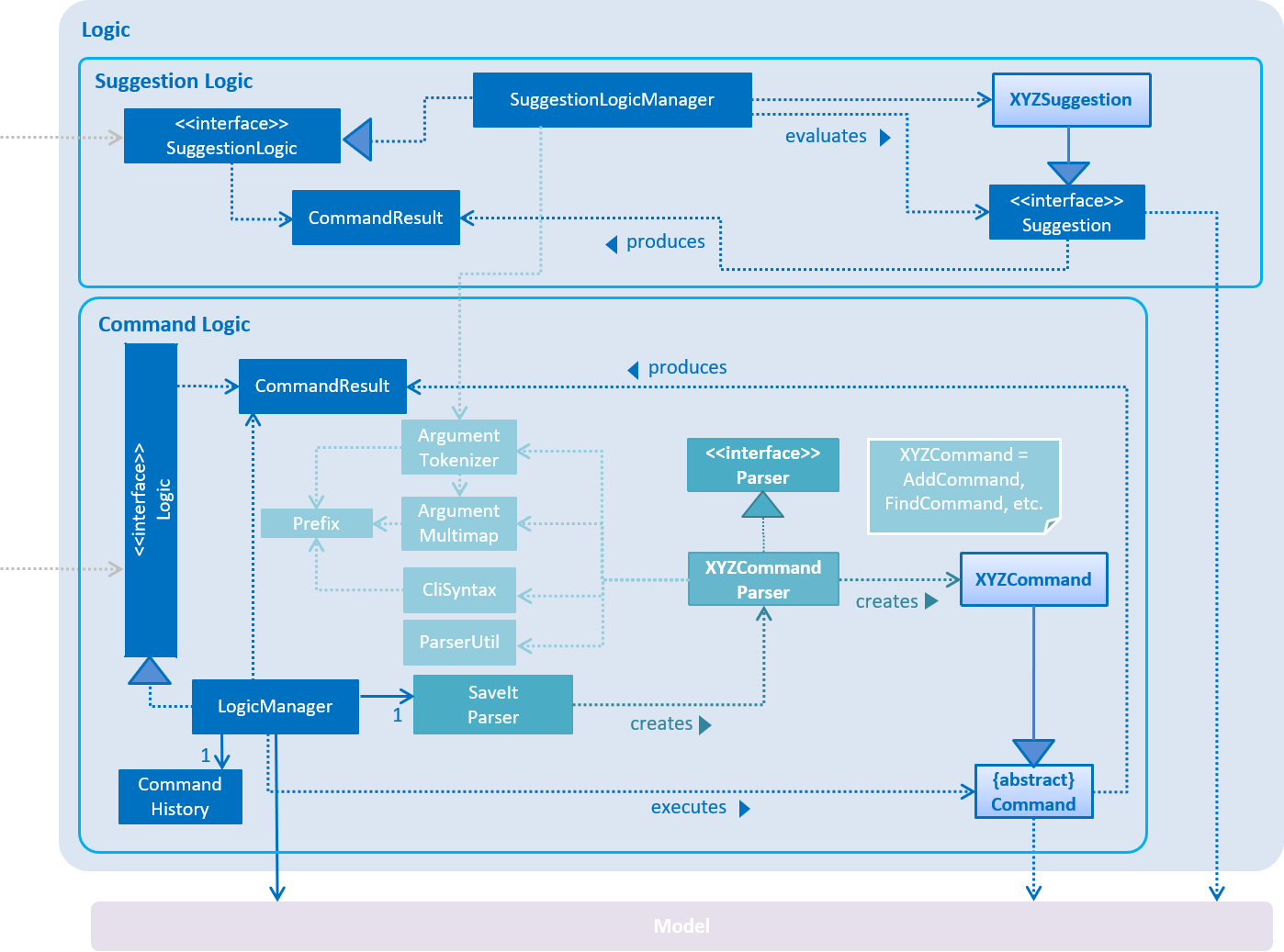
3.3. Logic component
The Logic Component can be split into two subcomponents:
1. Command Logic Subcomponent
The command logic subcomponent encapsulates the execution of all commands. Each command is represented its own class (e.g. FindCommand.java, AddCommand.java) which all inherit from an abstract Command.java class.
API :
Logic.java
-
Logicuses theSaveItParserclass to parse the user command. -
This results in a
Commandobject which is executed by theLogicManager. -
The command execution can affect the
Model(e.g. adding a statement) and/or raise events. -
The result of the command execution is encapsulated as a
CommandResultobject which is passed back to theUi.
2. Suggestion Logic Subcomponent
The suggestion logic subcomponent encapsulates the evaluation of user inputs as it is keyed into the command line, differing from the command logic in that command logic is only executed upon entering the command, whereas suggestion logic is called whenever the user input changes (without the need to enter).
API :
SuggestionLogic.java
-
SuggestionLogicparses user inputs whenever it changes. -
This determines which
Suggestionobject is created by theSuggestionLogicManager. -
The evaluation of the
Suggestionobject reads data from theModel(e.g. finds a specificIssue). -
The result of the evaluation is encapsulated as a
SuggestionResultobject which is passed back to theUi.
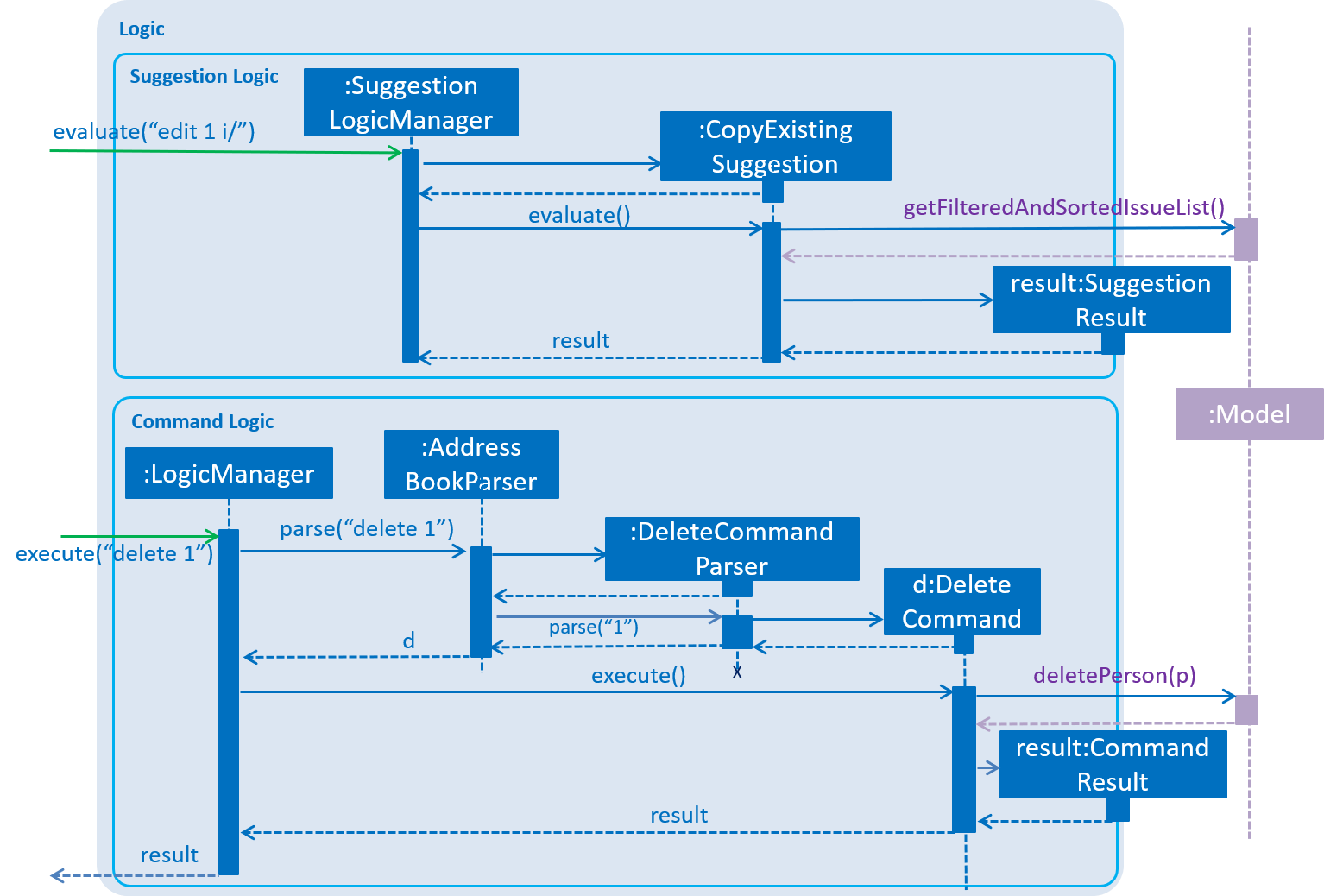
Given below is the Sequence Diagram for interactions within the Logic component when an API call is made. The Sequence Diagram is split into two branches of logic:
-
Command logic: Shows an example command execution of the
delete 1Command, which calls theDeleteCommand. -
Suggestion logic: Shows an example suggestion evaluation of the user input
edit 1 i/, which calls theCopyExistingSuggestion.
3.4. Model component
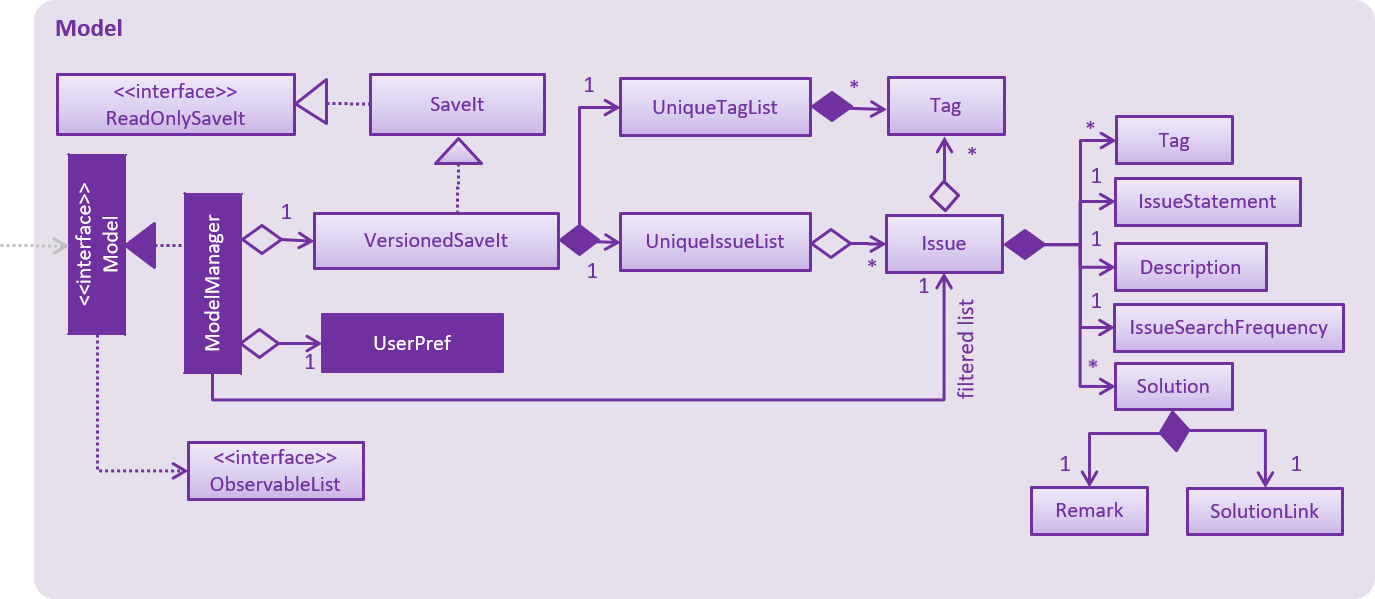
The Model Component contains the classes which are representations of the data stored by the application, and how each data objects are linked with each other.
API : Model.java
-
stores a
UserPrefobject that represents the user’s preferences. -
stores the SaveIt data.
-
exposes an unmodifiable
ObservableList<Issue>that can be 'observed' e.g. the UI can be bound to this list so that the UI automatically updates when the data in the list change. -
does not depend on any of the other three components.
|
3.5. Storage component
The Storage Component is the interface that involves reading and storing the data objects in XML files, which allows data to persist across multiple sessions.
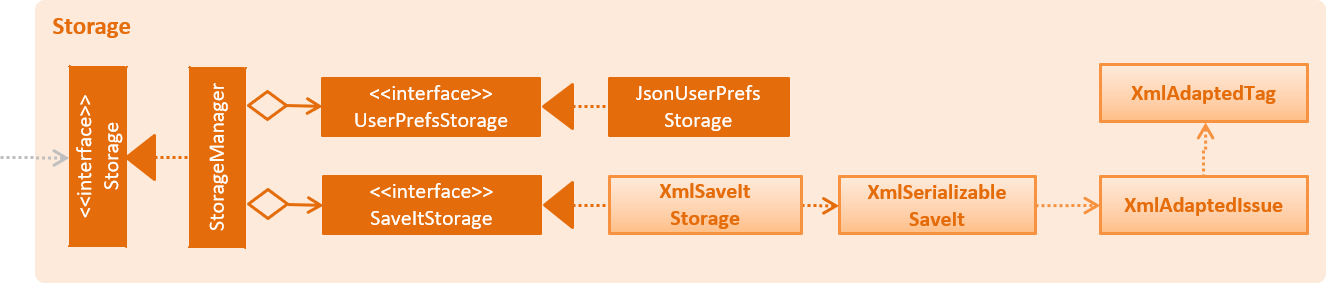
API : Storage.java
-
can save
UserPrefobjects in json format and read it back. -
can save the SaveIt data in xml format and read it back.
3.6. Common classes
Classes used by multiple components are in the seedu.saveit.commons package.
4. Implementation
This section describes some noteworthy details on how certain features are implemented. Note that this section does not fully encompass all the features, but the more core features of the application.
4.1. Add feature
The add command can add both issue and solution to SaveIt. It includes two levels:
-
Root level
-
Issue statement
-
Issue description
-
Issue tags
-
-
Issue level
-
Solution link
-
Solution remark
-
4.1.1. Add issue
Adding a new issue can only happen at the root level
Current implementation
The SaveItParser is used to call AddCommandParser so as to pass the entered issue. In order to build a new Issue object, a dummy solution link and dummy solution remark will be used. After that, AddCommand is invoked which will ask model to add the issue to the Model component.
In order to store the new issue inside the SaveIt, VersionedSaveIt will be invoked and it will add issue to the UniqueIssueList.
The following sequence diagram illustrates how the add new issue feature functions:
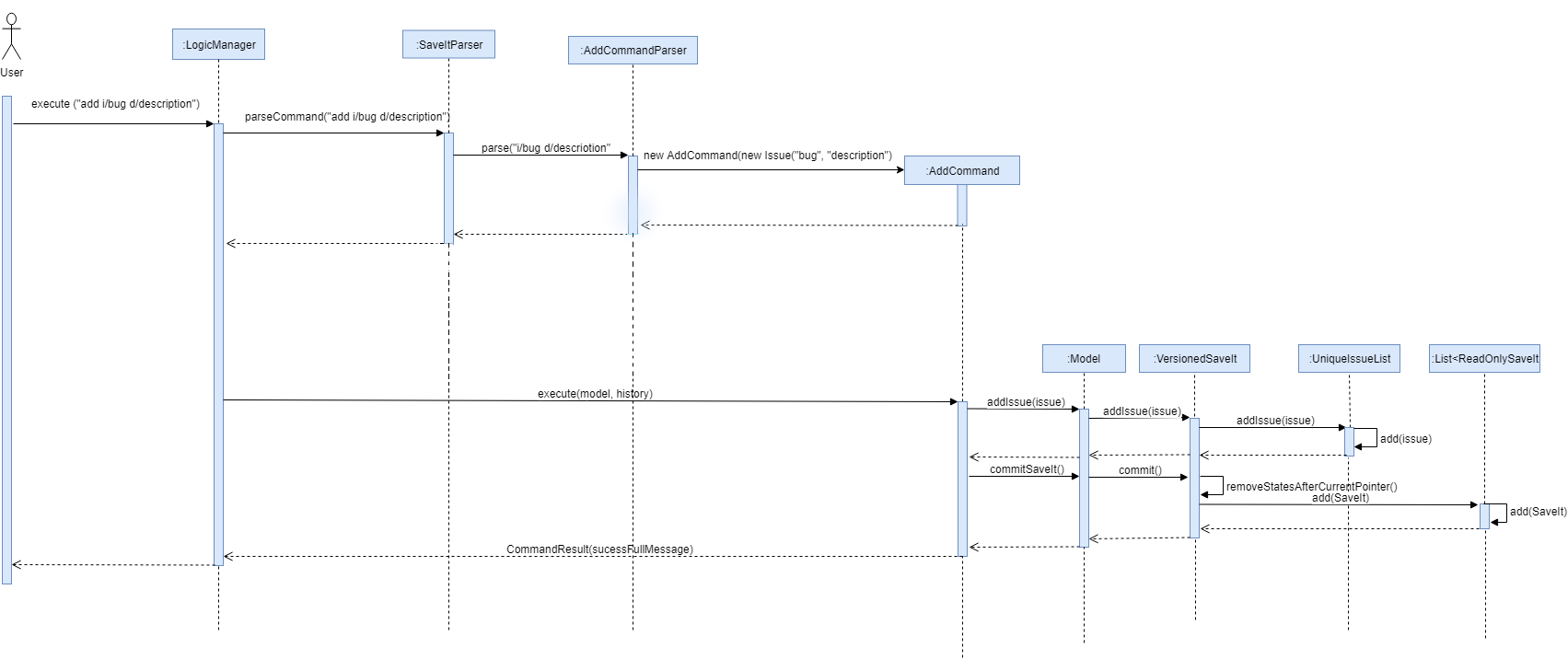
This diagram gives a clear procedure that how the user input is passed step by step by calling different methods and objects in different sequences.
4.1.2. Add solution to existing issue
Adding a new solution can only happen at the issue level
Current implementation
The SaveItParser is used to call AddCommandParser just like how adding issue feature functions as above mentioned. However, this time, the new solution link and solution remark is provided to AddCommand instead. In order to build a new Issue object, dummy issue statement and dummy issue description will be used. During execution, addSolution method, which was newly added, in Model component will be invoked to add the solution. The detailed implementation of addSolution in model component is quite simple. Since the list stored in application is immutable, each time, a new issue will be created with original statement and description, then the new solution will be added to that particular issue. Finally, updateIssue method will be called to replace the issue in versionedSaveIt.
The following sequence diagram illustrates how the add solution feature functions
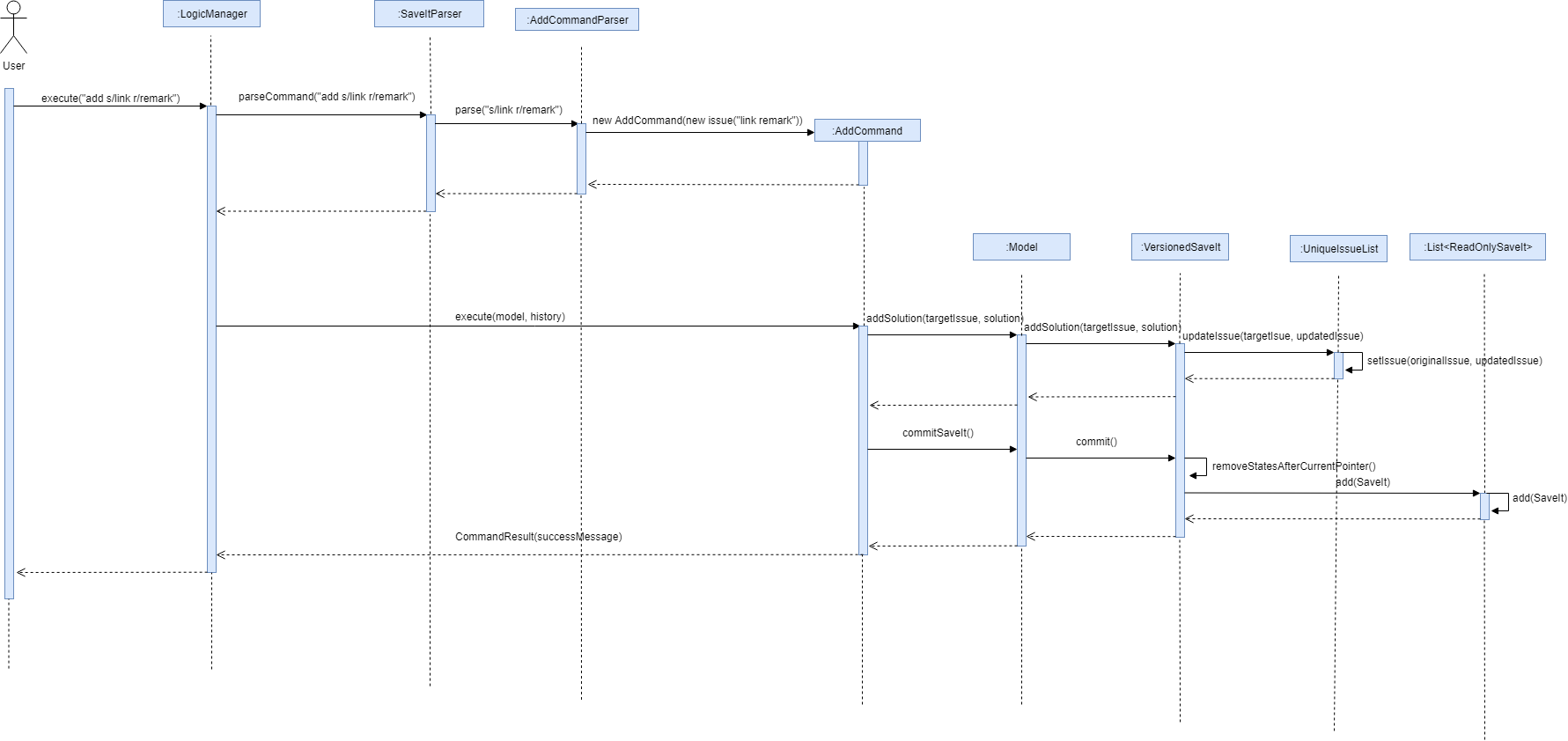
This diagram shows the sequence that how add solution command is executed. It could be also noticed that it is basically similar to that of add new issue feature besides it invokes updateIssue method in Model component rather than addIssue method.
4.1.3. Design Considerations
Aspect: How add solutions executes
-
Alternative 1 (current choice): Combine AddIssue and AddSolution together and distinguish them at the stage of
AddCommandParser-
Pros: Consistent syntax between the two features, so the command is more user-friendly.
-
Cons: Need to put more effort on distinguishing the difference between these two requests,
AddCommandParseris relatively complex compared to the other parser component.
-
-
Alternative 2: Build a new command especially for adding solution
-
Pros: Easy to implement.
-
Cons: The command set becomes too complex for the user.
-
Aspect: How add command distinguishes between adding solution and adding issue
-
Alternative 1 (current choice): Pass a newly created issue with dummy issue statement or dummy solution link
-
Pros: Consistent coding style and less change on logic structure
-
Cons: Quite complex implementation compared to other command
-
-
Alternative 2: Overload Issue constructor so that different issues will be passed to
AddCommandaccordingly.-
Pros: Relatively easier to implement
-
Cons: Lots of changes on structure.
-
4.2. Sort feature
The sort command can sort an issue list shown in the GUI.
4.2.1. Current implementation
We use JavaFX SortedList and the Comparator provided by SortType to sort the list.
In order to allow sorting to work with the filtered list, we wrap FilteredList with SortedList and retrieve this new list with a new method getFilteredAndSortedList().
The following sequence diagram illustrates how the mechanism works:
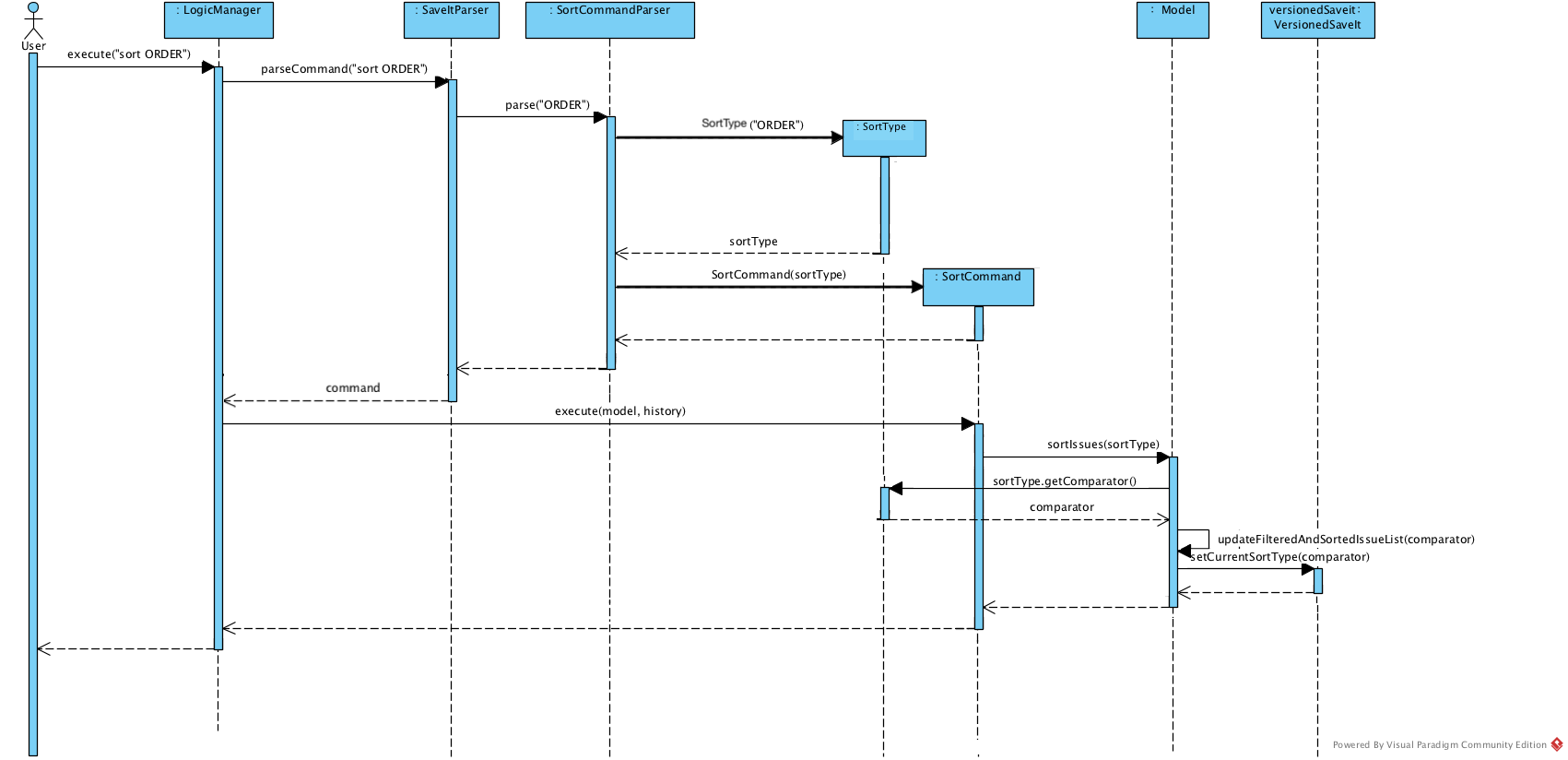
This diagram shows that after the input is parsed, a SortType object is initialized before the SortCommand object.
As shown in the diagram, a SortType object can provide the required comparator and we use the retrieved Comparator to sort the list when the sort command is executed.
The following is a class diagram for SortType.
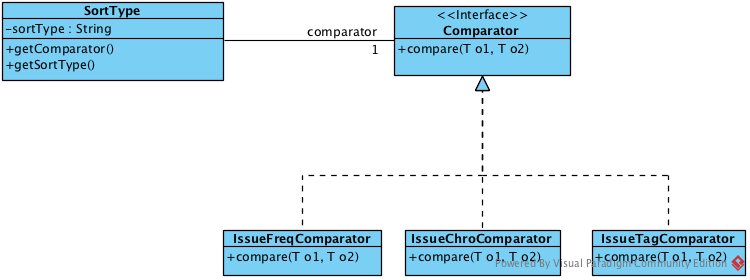
It shows that Comparator is an attribute of SortType class. We create three different classes that implement the Comparator Interface. They can serve the three sort types (excluding the default one) we provide in SaveIt. When more sort types are needed, we can simply create another class implementing Comparator, and add another case in the switch statement.
4.2.2. Design Considerations
Aspect: How sort executes
-
Alternative 1 (current choice): Combine SortedList and FilteredList, sort at GUI side
-
Pros: Consistent sorting. Doesn’t affect the memory of issue lists.
-
Cons: Need efforts to make sure the correct list is retrieved.
-
-
Alternative 2: Reconstruct UniqueIssueList directly, sort in Storage
-
Pros: Easy to understand and implement.
-
Cons: Break the persistence of the backend list.
-
4.3. Undo/Redo feature
4.3.1. Current Implementation
The undo/redo mechanism is facilitated by VersionedSaveIt.
It extends saveit with an undo/redo history, stored internally as an saveItStateList and currentStatePointer.
Additionally, it implements the following operations:
-
VersionedSaveIt#commit()— Saves the current SaveIt state in its history. -
VersionedSaveIt#undo()— Restores the previous SaveIt state from its history. -
VersionedSaveIt#redo()— Restores a previously undone SaveIt state from its history.
These operations are exposed in the Model interface as Model#commitSaveIt(), Model#undoSaveIt() and Model#redoSaveIt() respectively.
Given below is an example usage scenario and how the undo/redo mechanism behaves at each step.
Step 1. The user launches the application for the first time. The VersionedSaveIt will be initialized with the initial SaveIt state, and the currentStatePointer pointing to that single SaveIt state.

Step 2. The user executes delete 5 command to delete the 5th statement in the SaveIt. The delete command calls Model#commitSaveIt(), causing the modified state of the SaveIt after the delete 5 command executes to be saved in the saveItStateList, and the currentStatePointer is shifted to the newly inserted SaveIt state.
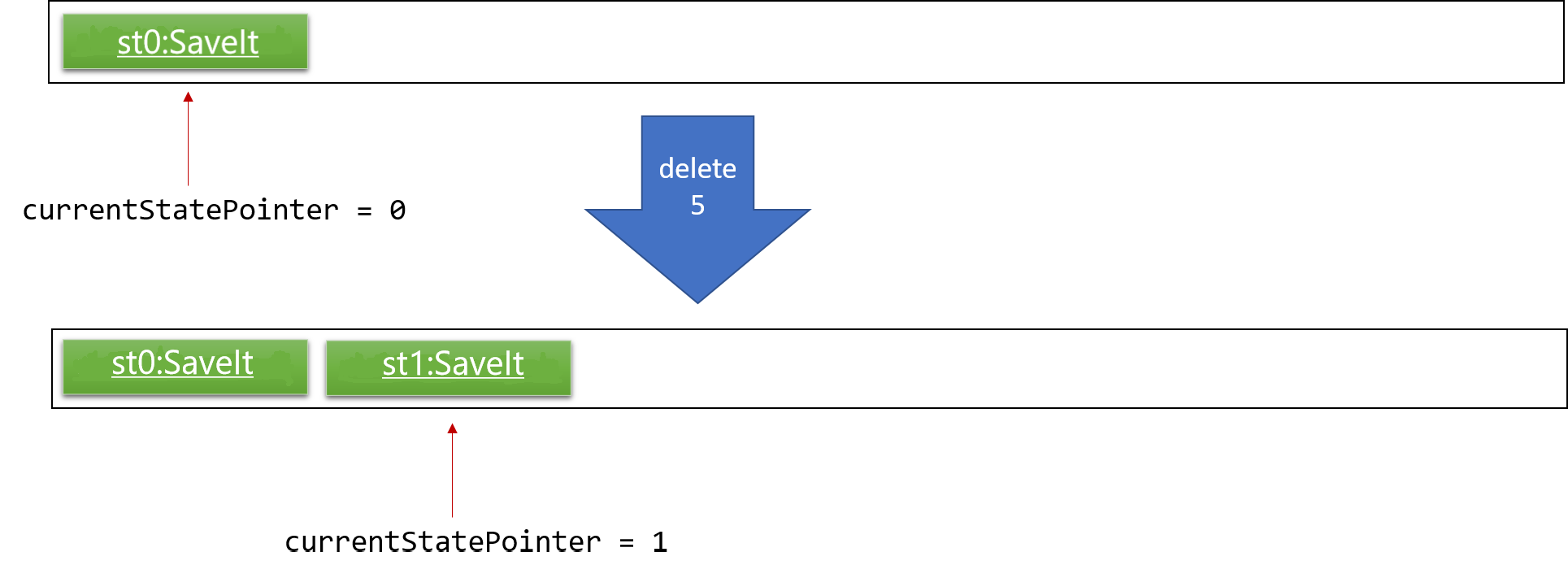
Step 3. The user executes add i/Array… to add a new issue. The add command also calls Model#commitSaveIt(), causing another modified SaveIt state to be saved into the saveItStateList.
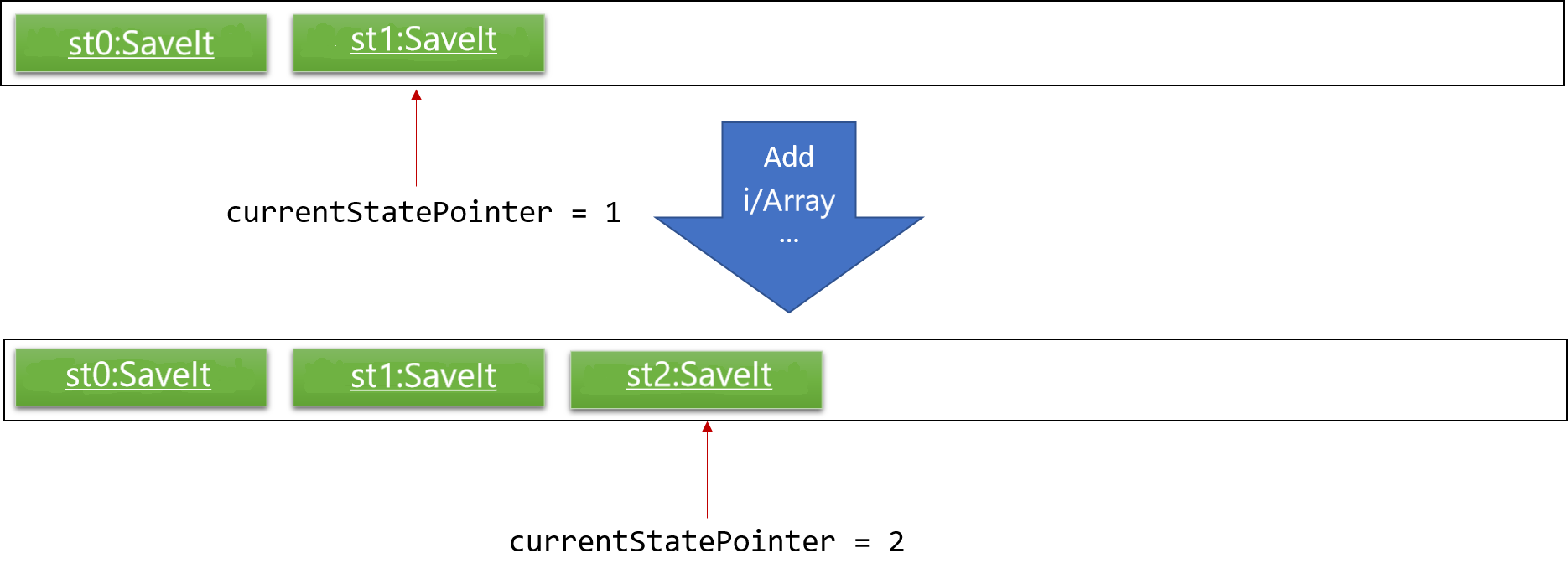
If a command fails its execution, it will not call Model#commitSaveIt(), so the SaveIt state will not be saved into the saveItStateList.
|
Step 4. The user now decides that adding the issue was a mistake, and decides to undo that action by executing the undo command. The undo command will call Model#undoSaveIt(), which will shift the currentStatePointer once to the left, pointing it to the previous SaveIt state, and restores the SaveIt to that state.
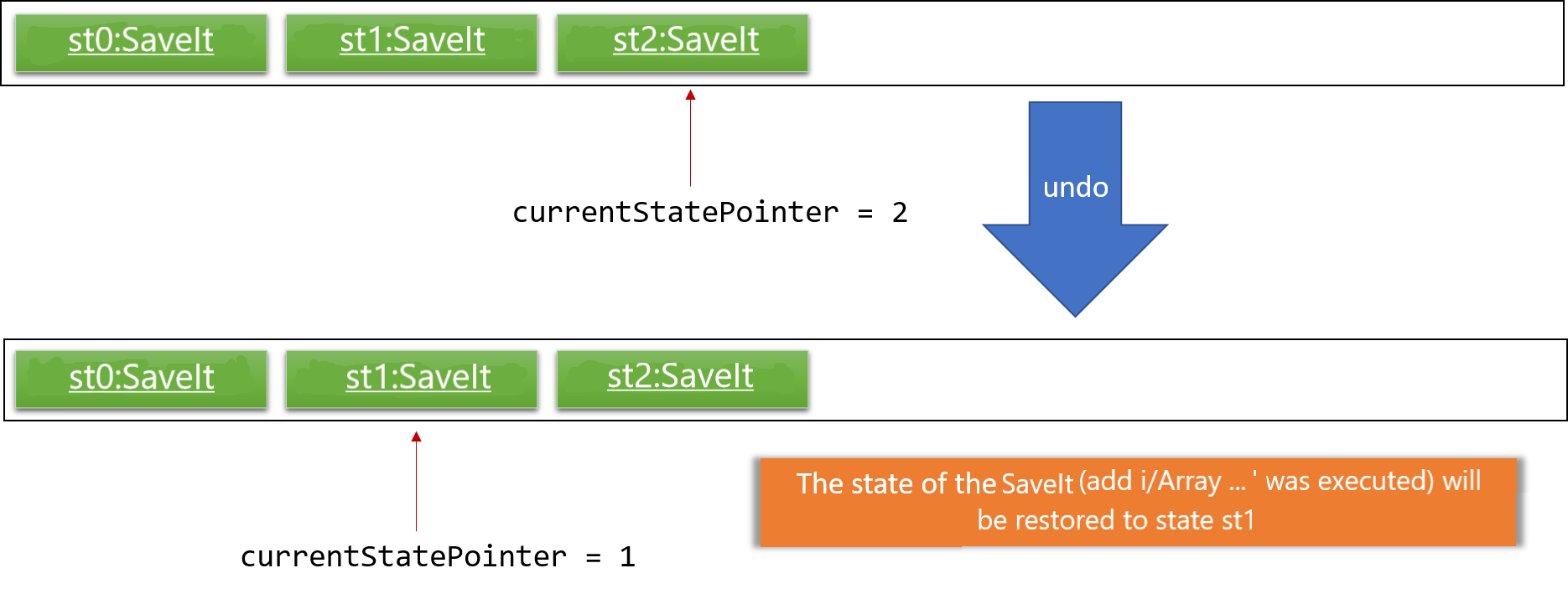
If the currentStatePointer is at index 0, pointing to the initial SaveIt state, then there are no previous SaveIt states to restore. The undo command uses Model#canUndoSaveIt() to check if this is the case. If so, it will return an error to the user rather than attempting to perform the undo.
|

The redo command does the opposite — it calls Model#redoSaveIt(), which shifts the currentStatePointer once to the right, pointing to the previously undone state, and restores the SaveIt to that state.
If the currentStatePointer is at index saveItStateList.size() - 1, pointing to the latest SaveIt state, then there are no undone SaveIt states to restore. The redo command uses Model#canRedoSaveIt() to check if this is the case. If so, it will return an error to the user rather than attempting to perform the redo.
|
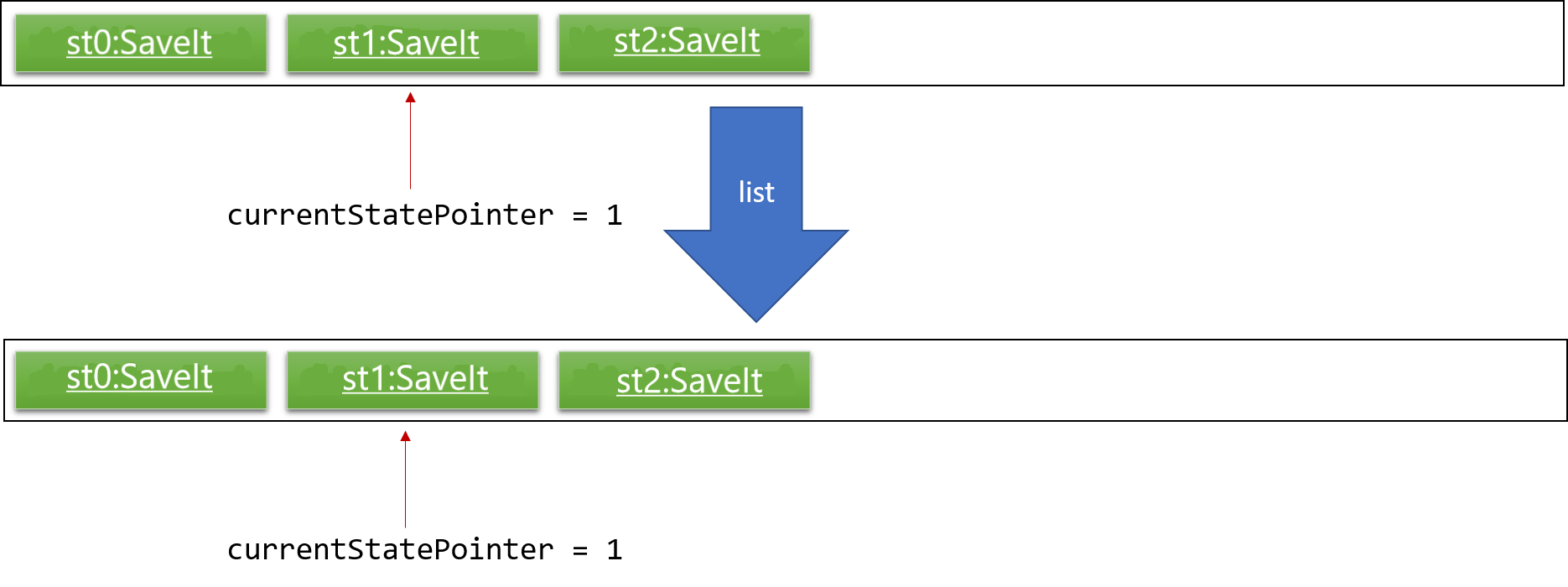
Step 5. The user then decides to execute the command list. Commands that do not modify the SaveIt, such as list, will usually not call Model#commitSaveIt(), Model#undoSaveIt() or Model#redoSaveIt(). Thus, the saveItStateList remains unchanged.
Step 6. The user executes clear, which calls Model#commitSaveIt(). Since the currentStatePointer is not pointing at the end of the saveItStateList, all SaveIt states after the currentStatePointer will be purged. We designed it this way because it no longer makes sense to redo the add i/Array … command. This is the behavior that most modern desktop applications follow.
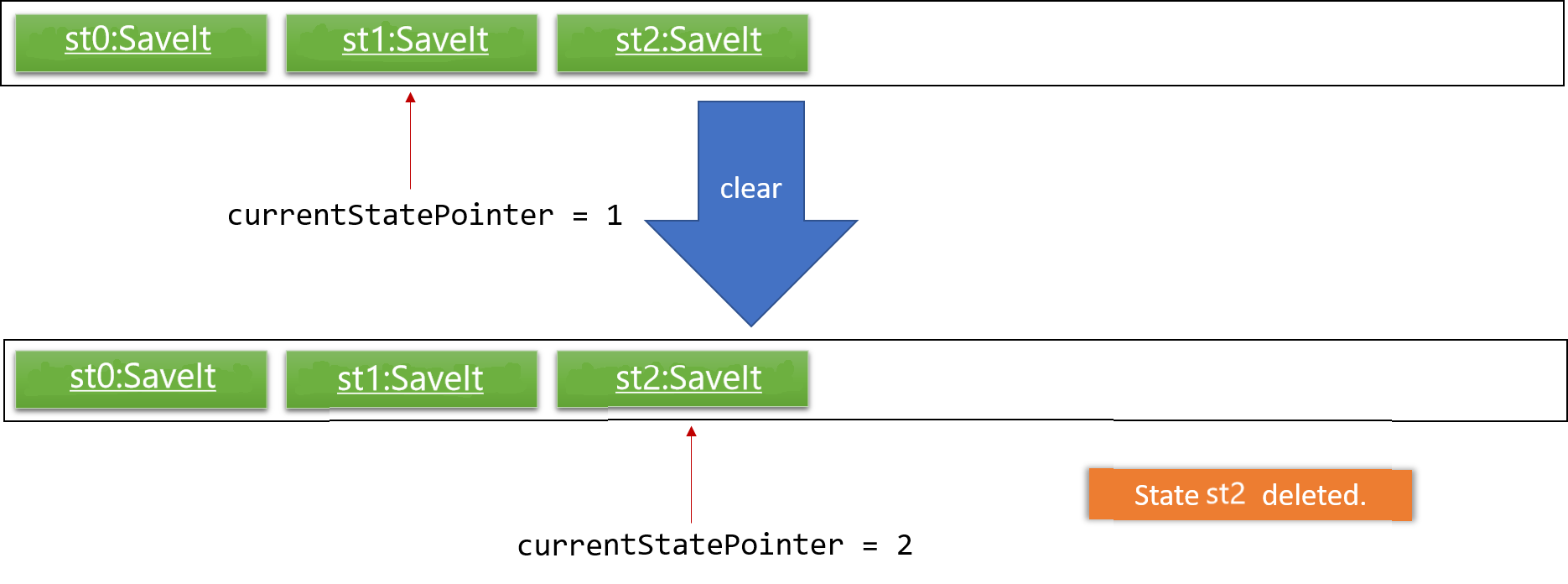

4.3.2. Design Considerations
Aspect: How undo & redo executes
-
Alternative 1 (current choice): Save the entire SaveIt.
-
Pros: Easy to implement.
-
Cons: May have performance issues in terms of memory usage.
-
-
Alternative 2: Implement redo/undo individually for each of the commands.
-
Pros: Will use less memory (e.g. for
delete, just save the statement being deleted). -
Cons: We must ensure that the implementation of each individual command are correct.
-
Aspect: Data structure to support the undo/redo commands
-
Alternative 1 (current choice): Use a list to store the history of SaveIt states.
-
Pros: Easy for new Computer Science student undergraduates to understand, who are likely to be the new incoming developers of our project.
-
Cons: Logic is duplicated twice. For example, when a new command is executed, we must remember to update both
HistoryManagerandVersionedSaveIt.
-
-
Alternative 2: Use
HistoryManagerfor undo/redo-
Pros: We do not need to maintain a separate list, and just reuse what is already in the codebase.
-
Cons: Requires dealing with commands that have already been undone: We must remember to skip these commands. Violates Single Responsibility Principle and Separation of Concerns as
HistoryManagernow needs to do two different things.
-
4.4. Confirmation Check
Some commands that can affect the users' experience significantly need to be paid attention to and confirmation should be provided before they are executed.
For the current version, clear is the only command that needs confirmation.
4.4.1. Current Implementation
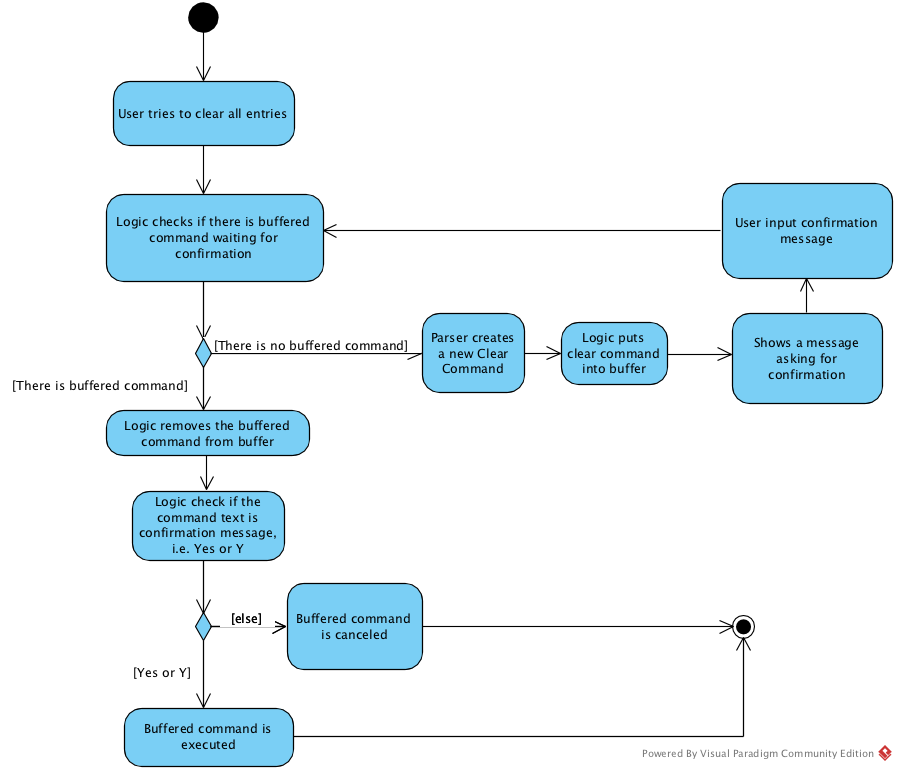
As shown in the diagram, instead of letting Logic execute the command directly after parsing it, we now check if we need confirmation before the command is executed.
In order to connect the confirmation with the command:
Step 1. We buffer the command that requires confirmation.
Step 2. Wait for the user to input confirmation message.
Step 3. Clear the buffer.
Step 4. Generate the CommandResult according to the confirmation message entered.
4.4.2. Design Consideration
Aspect: How to distinguish commands that need confirmation
-
Alternative 1 (current choice): Use abstract class DangerCommand
-
Pros: Protect the specific Command type from being accessed by LogicManager. Sustainable.
-
Cons: N.A.
-
-
Alternative 2: Check class name and provide a danger class name list
-
Pros: Easy to implement.
-
Cons: Command information leaked. Inaccurate, e.g. two classes from different packages can have the same class name.
-
Aspect: How to connect the confirmation message with the command requiring it
-
Alternative 1 (current choice): Buffer the command
-
Pros: Protect CommandBox from being accessed by Command, i.e. retrieve the input message in Command Class
-
Cons: Another variable introduced. Need efforts to deal with the buffered command properly.
-
-
Alternative 2: Let Command check the confirmation message
-
Pros: Follow the normal logic. Easy to understand.
-
Cons: CommandBox is exposed to Command Class.
-
4.5. Logging
We are using java.util.logging package for logging. The LogsCenter class is used to manage the logging levels and logging destinations.
-
The logging level can be controlled using the
logLevelsetting in the configuration file (See Section 4.6, “Configuration”) -
The
Loggerfor a class can be obtained usingLogsCenter.getLogger(Class)which will log messages according to the specified logging level -
Currently log messages are output through:
Consoleand to a.logfile.
Logging Levels
-
SEVERE: Critical problem detected which may possibly cause the termination of the application -
WARNING: Can continue, but with caution -
INFO: Information showing the noteworthy actions by the App -
FINE: Details that is not usually noteworthy but may be useful in debugging e.g. print the actual list instead of just its size
4.6. Configuration
Certain properties of the application can be controlled (e.g App name, logging level) through the configuration file (default: config.json).
4.7. Directory Level Model
SaveIt manages a list of issues, with each issue containing a list of solutions. To manage the data with two-level structure, SaveIt implemented a directory model in the Model component and UI component.
4.7.1. Current Implementation
Currently a directory class is maintained in SaveIt. It consist of root level and issue level.
The solution level is disabled for now as the complexity of current version of SaveIt
does not require the three-level directory system.
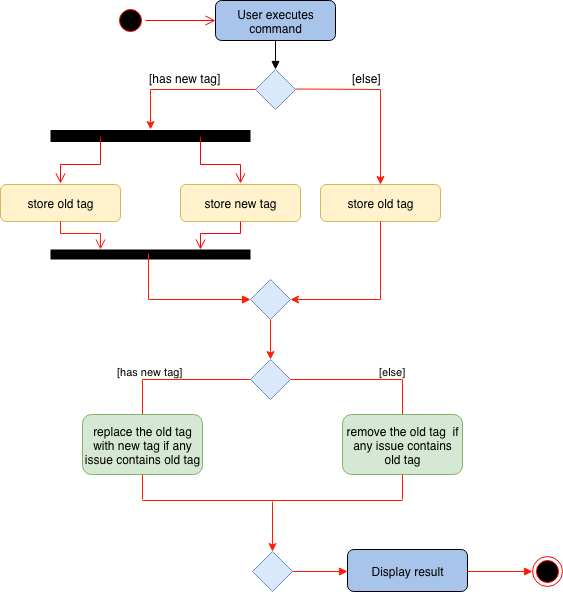
Command Execution
Before any command is executed,
it will query the current directory and determine the command result.
Some commands will have different command word and command result at different directory, such as:
edit, add. Some commands can only be executed at root level
, such as sort, addtag, refactortag, find, findtag.
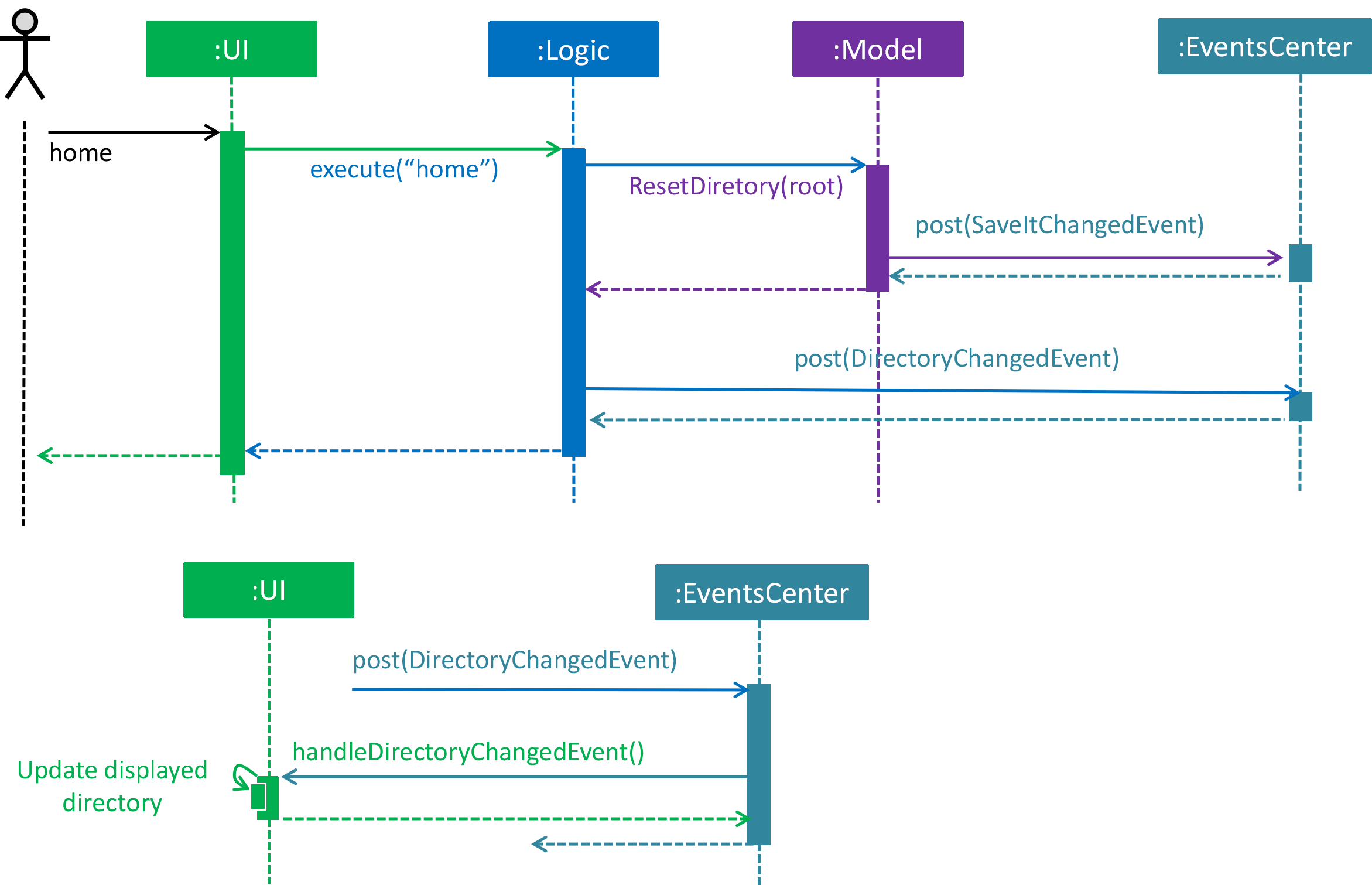
Home Command
To traverse between root and issue level, a new command home is added to the command list.
home Command changes the current directory to root level and post DirectoryChangedEvent,
which invokes the UI to load the issue list in the list panel. It is shown in the sequence
diagram below
4.7.2. Design Consideration
Aspect: How to manage the issues and solutions with two-level structure
-
Alternative 1 (current choice): Implement a directory level model explicitly.
-
Pros: The data structure is clearer. Target users are familiar with director level system, such as file system in Linux.
-
Cons: Changing directory may be inconvenient for users.
-
-
Alternative 2: Manage the issue-solution structure by specifying index in commands.
-
Pros: No need to change the previous structure.
-
Cons:The structure is not clear and the users may be confused.
-
4.8. UI Enhancement
The figures below show the current UI for SaveIt v1.4.
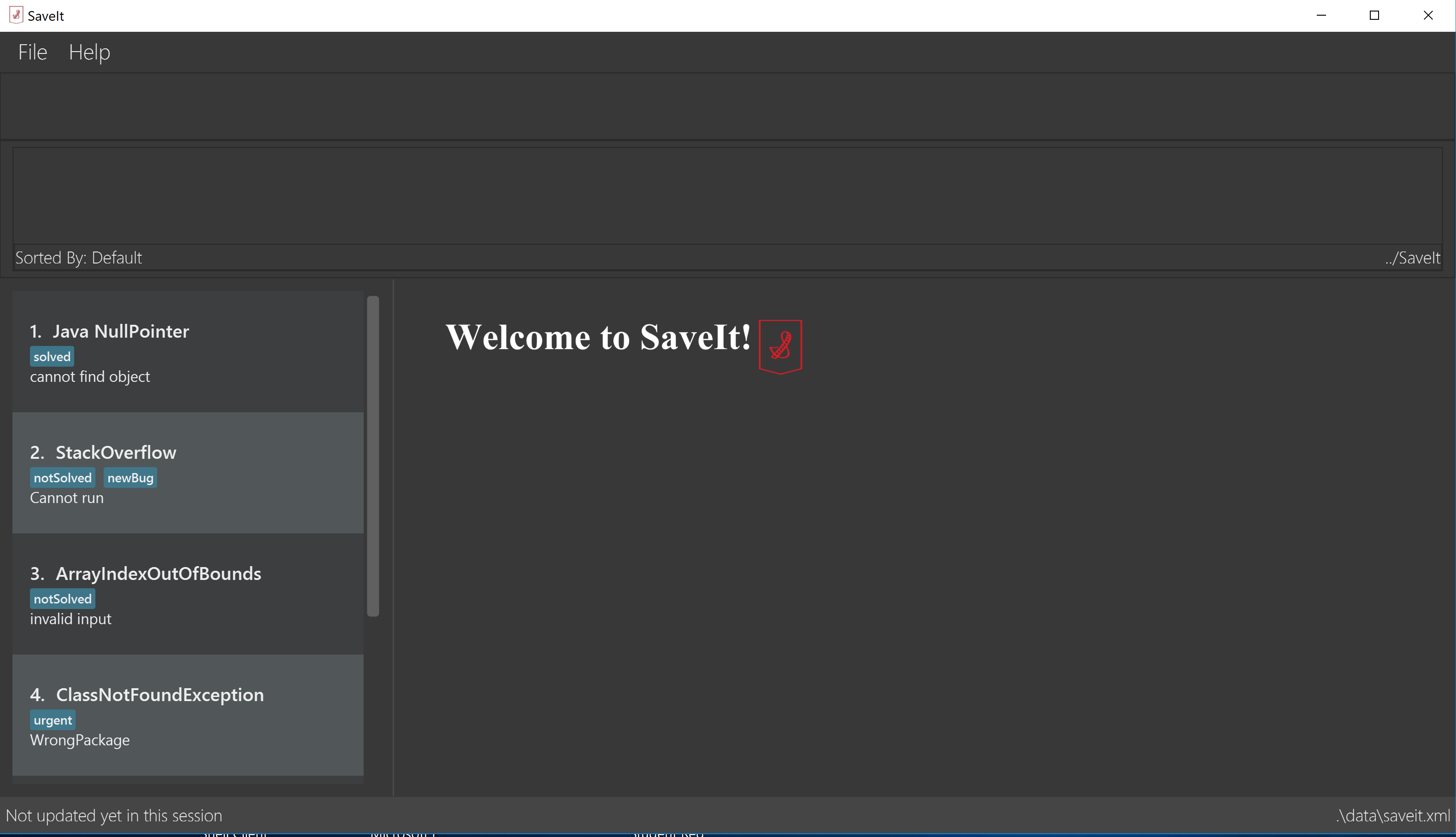
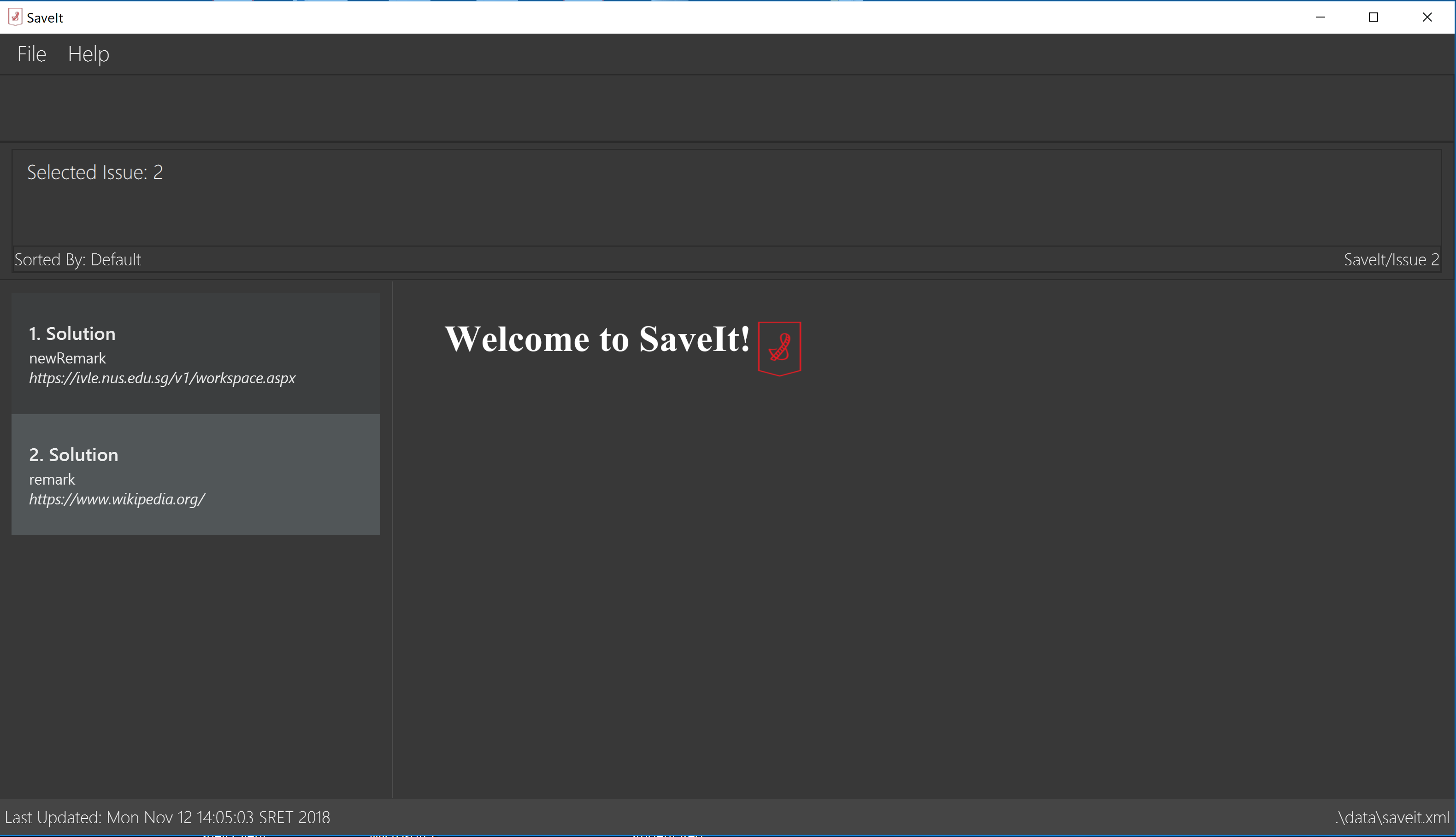
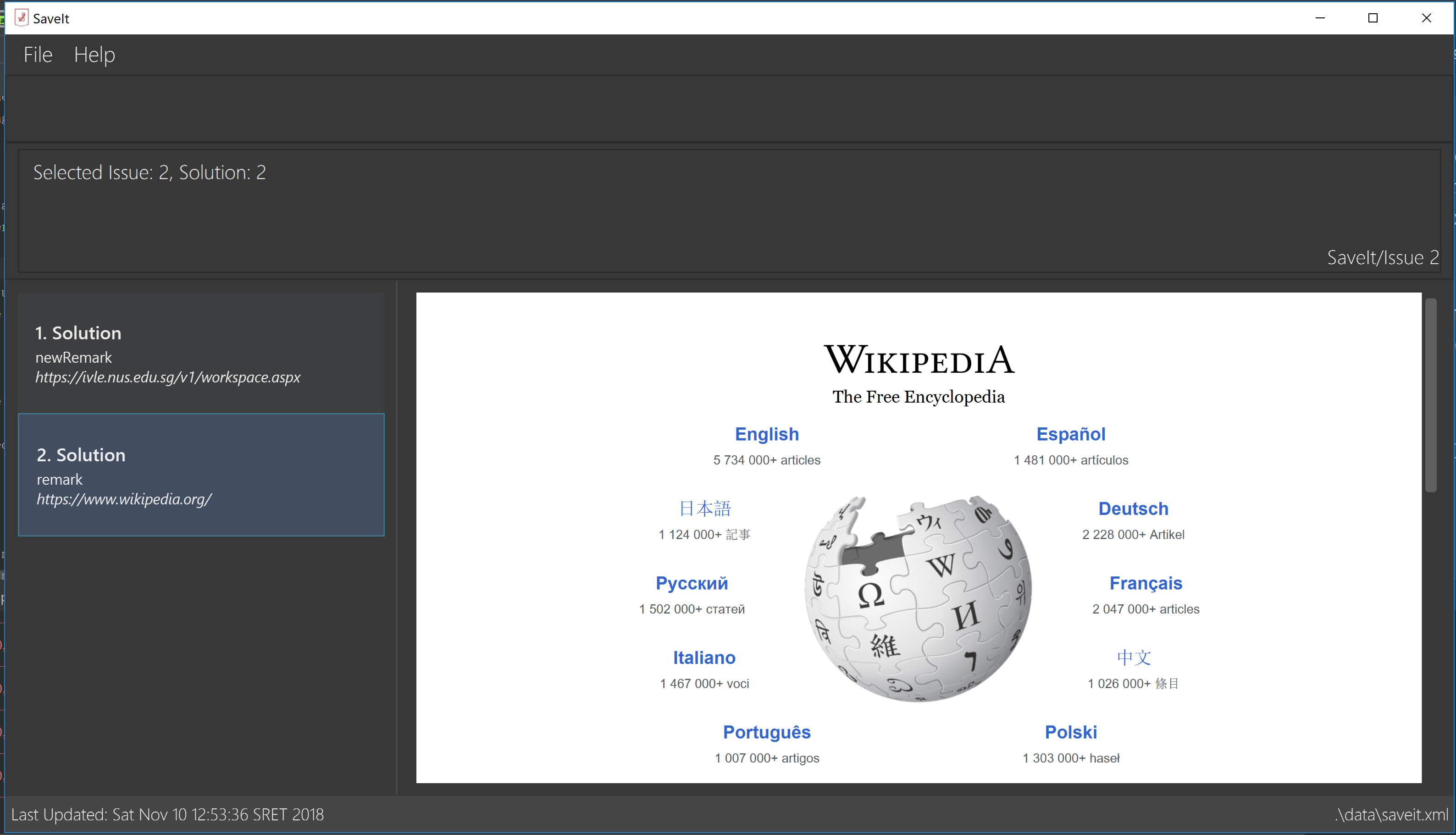
In the above figures, the left column is the list panel which displays the list of issues or the list of solutions. The browser panel at bottom right displays the web page of the url as in the solution link. When no page is loaded, it displays the default page as above. Whenever a solution is selected, the browser panel loads the url given in the solution link as below.
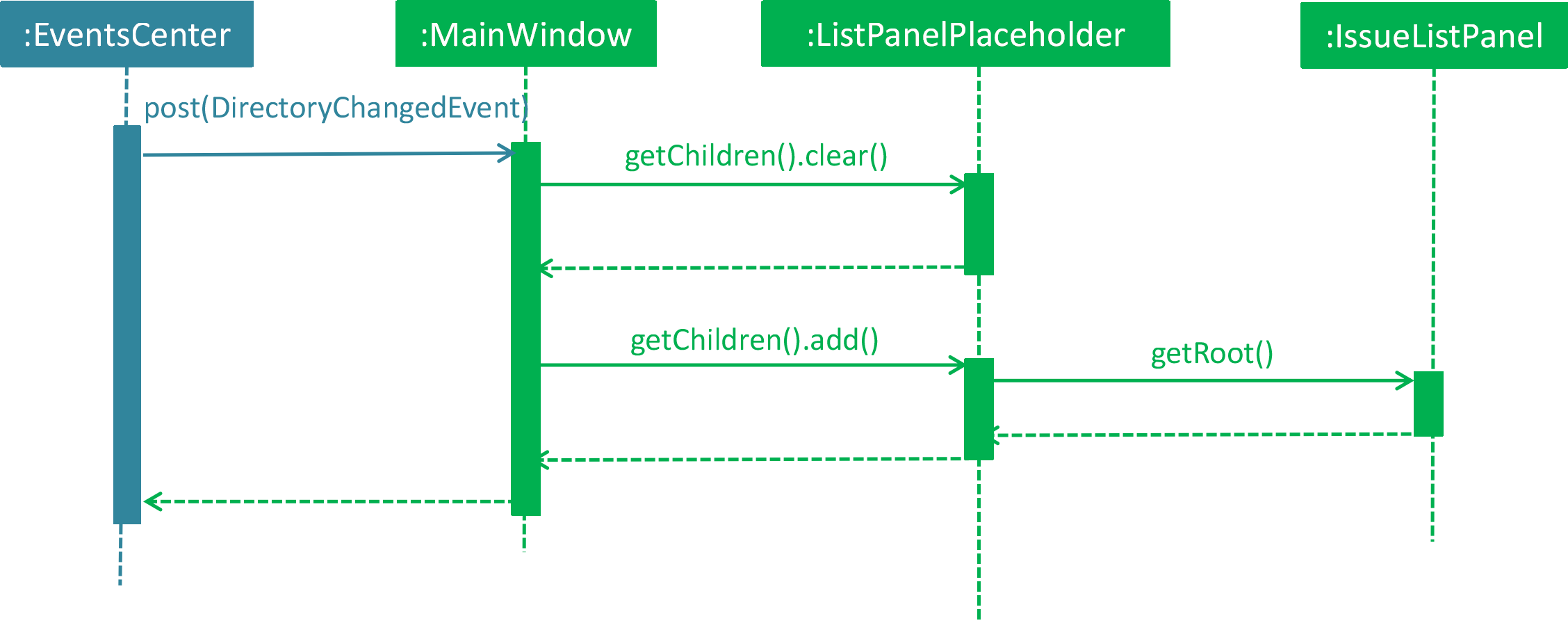
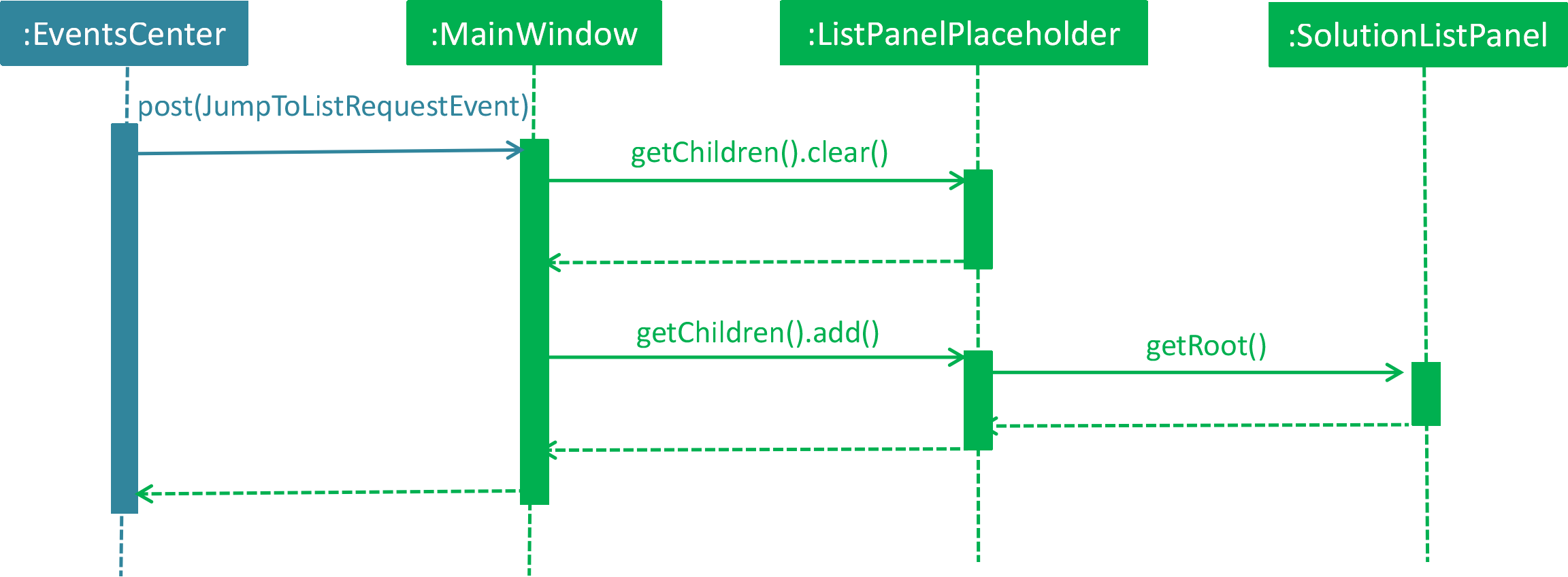
4.8.1. Current Implementation
Currently the list panel implements a two-level structure. When the directory is at root level, it displays
a list of issues. When the directory is at issue level, it displays the solution list of the selected issue.
The list panel interacts with other components through DirectoryChangedEvent and JumpToListRequestEvent.
The sequence diagram is as shown below.
4.8.2. Design Consideration
-
Alternative 1 (current choice): Use one panel and switch between the two list.
-
Pros: The panel takes less space. It also represents the directory structure model in UI.
-
Cons: Need to switch between lists. Cannot display the issues while displaying the solutions.
-
-
Alternative 2: Use two panels to display the issue list and solution list.
-
Pros: Both lists can be viewed at the same time. Implementation is easier.
-
Cons: It takes too much space in the UI.
-
4.9. Edit Feature
The edit feature allows users to edit any field of the issue and solution.
4.9.1. Current Implementation
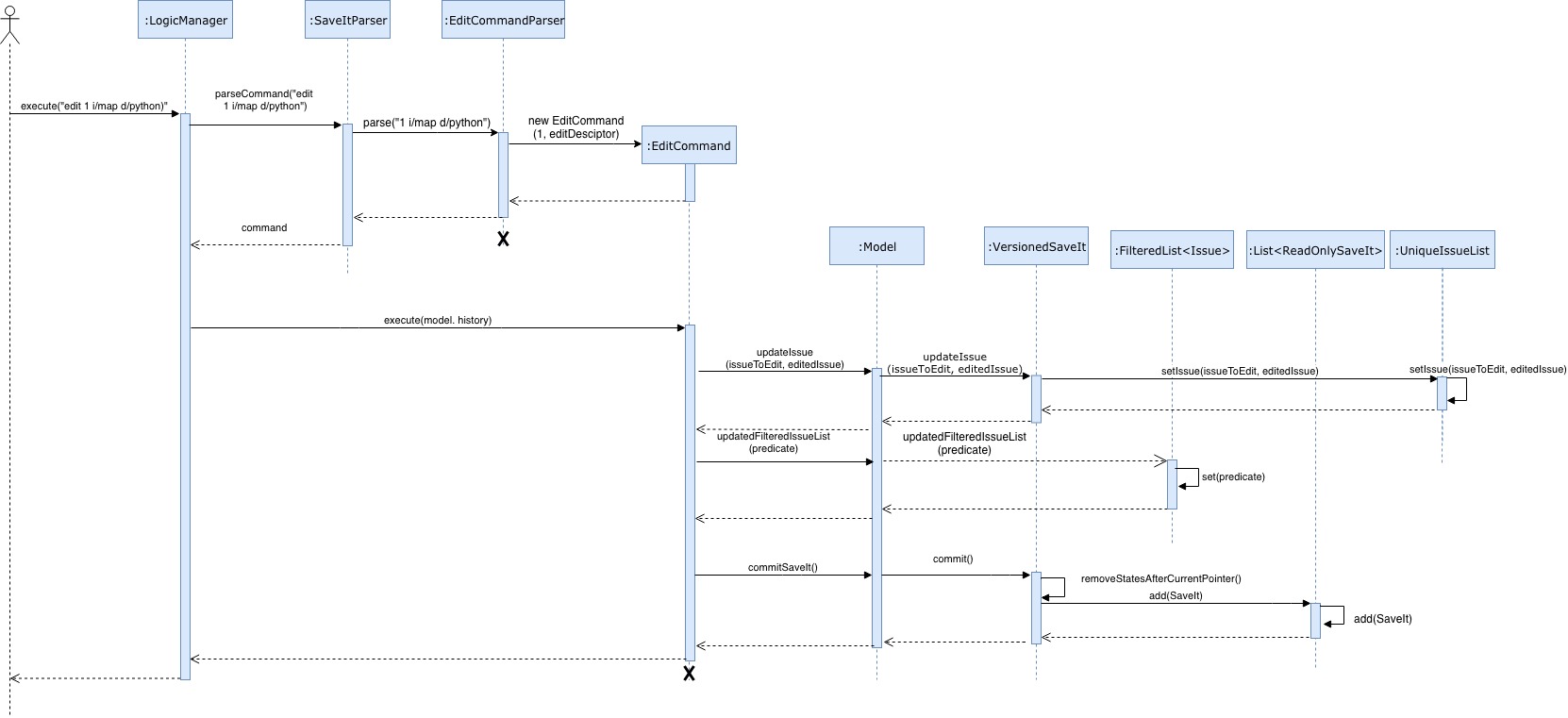
The edit mechanism is facilitated by editCommandParser and editCommand. Users are allowed to edit any field in the issue list.
The editCommandParser extends Parser and implements the following operations:
-
editCommandParser#parser(String args)-
Checks the arguments for empty strings and throws a
ParseExceptionif empty string is found. -
Analyses the argument to check if it is a valid command format. If it is a valid format, it will set the corresponding filed using
EditDescriptor. There are two types format.-
edit issue: edit Index i/statement d/description t/tag1 t/tag2 …
-
edit solution:
edit Index s/https://www.dummysolutionlink.com r/remark.
-
-
If it fails to parse the command, it will throw ParseException and display edit command usage message.
-
editCommand#execute(Model model, CommandHistory history)-
Analyses the user in the home directory or issue directory. Since the home directory can only edit issues, if user provides solution related command, it will fail to execute. Also, in the issue directory, it only allows to edit solution, it will fail to execute the issue related command. Then it will throw
CommandExceptionand show wrong directory information. -
Checks if the user index in editDescriptor is larger than the size of the issue list or solution list.
ThrowCommandExceptionand show invalid index warning. Otherwise, call the functionmodel.updateIssue(issueToEdit, editedIssue)to update issue list.
-
Please refer to the Sequence Diagram below for the illustration of edit operation.
4.9.2. Design Consideration
-
Alternative 1 (current choice): Update the whole issue fields when every single field needs to edit.
-
Pros: It is easy to implement in current implementation.
-
Cons: It may have performance issues regarding memory usage.
-
-
Alternative 2: Update the specific data field instead of updating the whole issue.
-
Pros: It will use less memory.
-
Cons: It has lower security if the issue is the mutable object.
-
4.10. Retrieve Feature
The retrieve feature allows user to choose a solution link and copy it to the system clipboard.
4.10.1. Current Implementation
The retrieve feature basically takes the user entered index and call getFilteredAndSortedList method in Model to get the selected solution. Then Java Toolkit package is used to copy the url link of solution to the system clipboard.
4.11. Set Primary Feature
The set primary feature allows users to choose one solution as primary.
4.11.1. Current Implementation
The set primary solution mechanism is facilitated by the method isPrimarySolution(), which is overrode by PrimarySolution inheriting from Solution.
4.11.2. Design Consideration
Aspect: How to distinguish between PrimarySolution and Solution
-
Alternative 1 (current choice): Use PrimarySolution as a subclass of Solution
-
Pros: No flag attribute is introduced. More sustainable.
-
Cons: New object is created. May affect performance.
-
-
Alternative 2: Add a flag attribute to Solution
-
Pros: Easy to understand and implement.
-
Cons: Solution constructor is affected. The flag attribute is redundant for non-primary solutions.
-
-
Alternative 3: Store the primary solution index in the solution list.
-
Pros: No new constructor and attribute are introduced.
-
Cons: Need to check if the index is affected every time when the solution list is updated.
-
4.12. Reset Primary Feature
The reset primary feature allows users to reset the primary solution and make all solutions normal and not highlighted.
4.12.1. Current Implementation
The reset primary solution mechanism goes through the solution list once and checks if a solution is primary or not. If it is primary, we replace it with a new Solution object with the same data of the primary solution. If it is not primary, we continue checking until we reach the end of the list.
4.13. Refactor Tag Feature
The refactor tag feature allows users to rename or remove a specified tag for all entries with that tag.
4.13.1. Current Implementation
The refactor tag mechanism is facilitated by RefactorTagCommandParser and RefactorCommand.
The RefactorTagCommandParser extends Parser and implements the following operations:
-
refactorTagCommandParser#parser(String args)-
Checks the arguments for empty strings and throws a
ParseExceptionif an empty string is found. -
Analyses the argument to check if it is a valid command format. Users are not allowed to provide other prefixes, except
t/andn/in refactor tag command.-
t/the tag that user wants to refactor, which must be input by users, otherwise throwsParserExceptionand shows refactor tag command usage message. -
n/the new tag that the user wants to replace the original one with, which is optional. (if the user does not provide, then remove the original one)
-
-
If it fails to parse the command, it will throw ParseException and display refactor tag command usage message.
-
refactorTagCommand#execute(Model model, CommandHisotry history)-
updates the issue list and returns success message if it has edited an issue, otherwise shows an unsuccessful message.
-
Iterates all the issues in the saveIt, if it contains the old tag, it will replace with the new tag if provided. Then update the list.
-
Please refer to the Sequence Diagram below for the refactor tag operation.
4.13.2. Design Consideration
Aspect: Implementation of RefactorTag command parser.
-
Alternative 1 (current choice): Allows only to rename or remove the old tags that user input lastly.
-
Pros: It is easy to implement.
-
Cons: It is inconvenient if the user wants to replace multiple tags once.
-
-
Alternative 2: Allows to rename or remove multiple old tags with multiple new tags.
-
Pros: It is convenient for users to replace or remove the tags once.
-
Cons: It is not clear for users to see the changes since tags are displayed disordered.
-
4.14. Add tag Feature
The add tag feature allows users to add Tag(s) to specified Indexed issues.
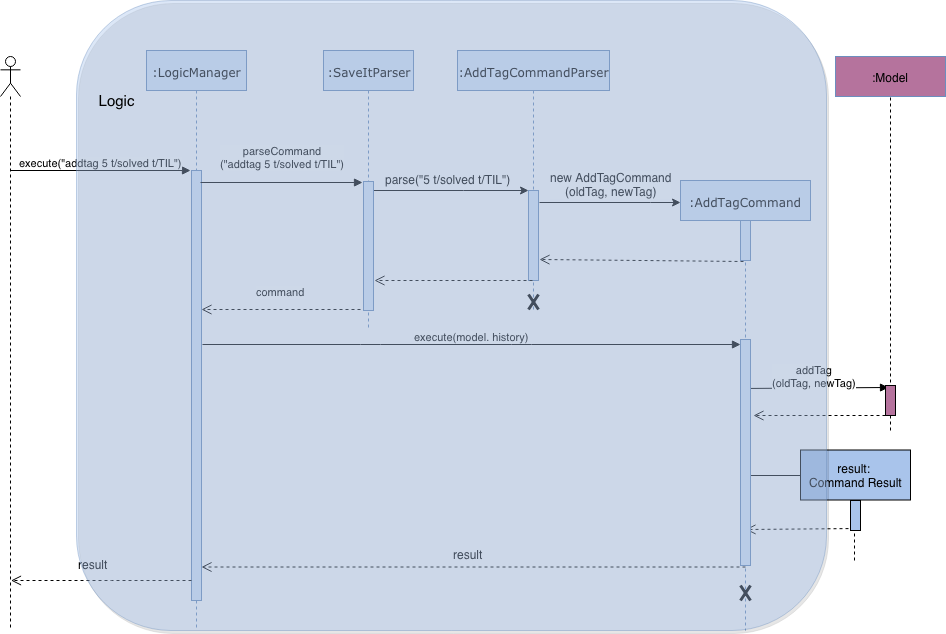
4.14.1. Current Implementation
The add tag mechanism is facilitated by AddTagCommandParser and AddTagCommand.
Please refer to the Sequence Diagram below for the illustration of add tag operation.
4.14.2. Design Consideration
Aspect: Implementation of AddTag command parser.
-
Alternative 1 (current choice): Allows a range of index and multiple indexes to be accepted as index parameter.
-
Pros: It is efficient to add multiple
Tagsto multiple issues instead of doing it singly. -
Cons: It has to consider various conditions of the user input.
-
-
Alternative 2: Creates an
IndexRangeclass for index.-
Pros: It is easy to understand and maintain.
-
Cons: It increases coupling between
IndexRangeclass andIndexclass
-
4.15. Suggestion Feature
The suggestion feature allows user to quickly complete commands by showing a drop-down window of suggested values when the user input matches a specific keyword or identifier.
4.15.1. Current Implementation
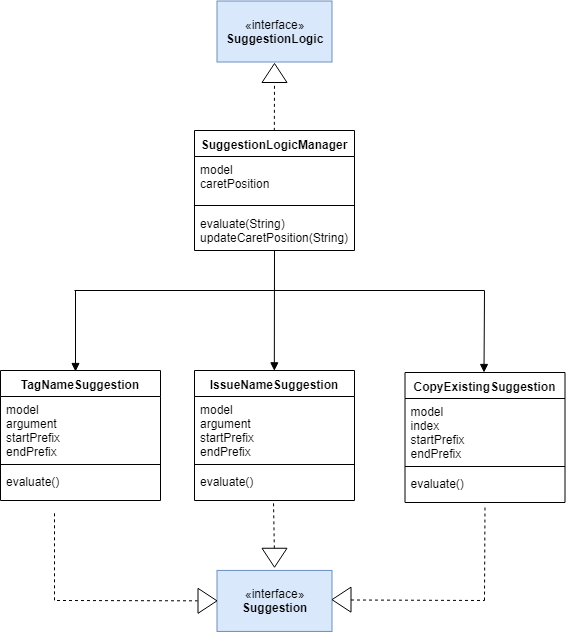
The figure below shows a basic relationship between each class.
The SuggestionLogicManager implements SuggestionLogic interface and overrides the evaluate method. Similarly, IssueNameSuggestion, TagNameSuggestion and CopyExistingSuggestion implement Suggestion interface and override evaluate method.
Since the suggestion component has to retrieve the data from model component to give a suggestion according to the user’s input, it is considered as a part of Logic component. By listening to changes in the text field, which is handled in CommandBox, the SuggestionLogicManager will be able to decide which type of suggestion should be given by parsing the following fields:
-
The command typed
-
The prefixes from
ArgumentTokenizer -
The caret position (position of the text cursor in the user input string)
For example, when entering find issueName as the user input, the command is parsed to match SuggestionLogicManager#parseFindCommandSuggestion. The prefixes are then matched accordingly and a new IssueNameSuggestion object will be instantiated. By calling Model#getCurrentIssueStatementSet, IssueNameSuggestion is able to find the relvant issue statements based on the user input. The returned SuggestionResult will be passed to the CommandBox#displaySuggestion method to handle the displaying of the results.
One thing to take note of, the drop-down window will be hidden once a user input is matched any given suggestion value.
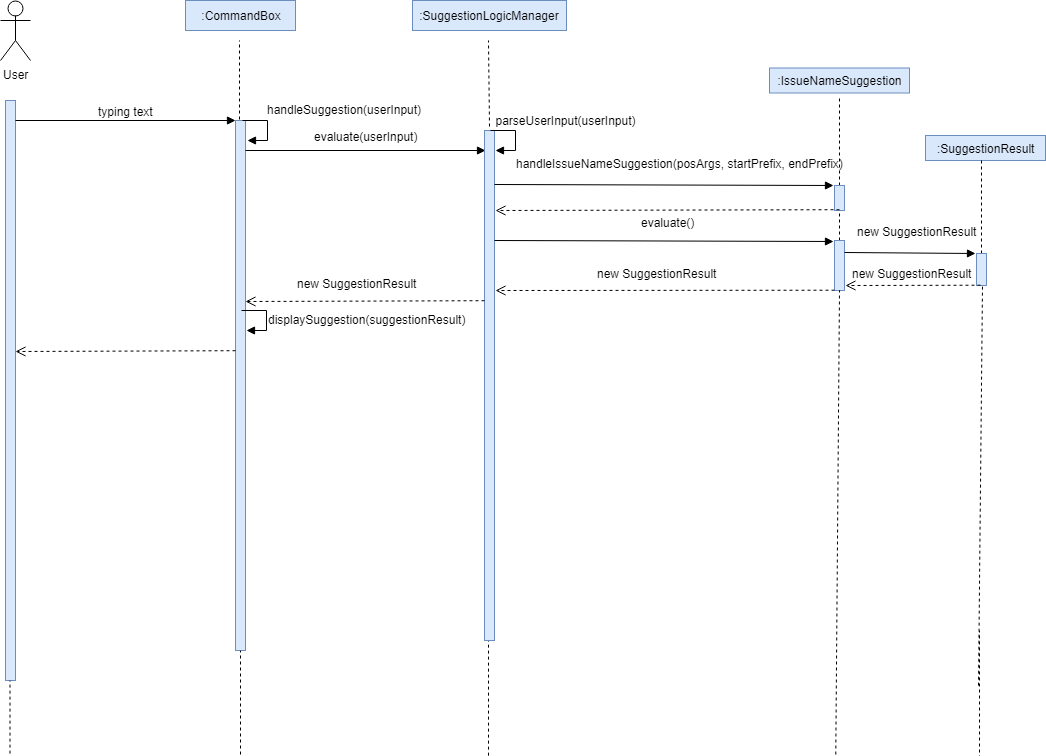
4.15.2. Design Consideration
Aspect 1: Architecture Design of the Suggestion Logic subcomponent
The architecture behind the Suggestion Logic subcomponent is designed by mimicking the original Logic component that handles the command logic. This is because the required implementation behind both is actually similar, needing to access both the Ui and the Model components. Hence, the SuggestionLogic and Suggestion are built similar to the original Logic component which has the corresponding classes Logic and Command that serves as interfaces to the Ui and Model components respectively. However, the internal implementation of the internal classes of the Suggesetion Logic subcomponent is different (i.e. Parser).
-
Alternative 1 (current choice): Create parser methods all within
SuggestionLogicManagerthat parse the user input directly - first parsing them based the commands (handled inSuggestionLogicManager#parseUserInput) and subsequently parsing based on thePrefixthat the text cursor is at.-
Pros: Keeps the code DRY.
-
Cons: Deviates from the original internal structure of the Command Logic subcomponent.
-
-
Alternative 2: Create parser classes for each command (e.g.
EditSuggestionParser) that handles the further parsing of thePrefixand creates the relevantSuggestionobject.-
Pros: Code is more modularized since the parsing is now handled by classes.
-
Cons: Code is repeated in each
SuggestionParserclass.
-
We use the first alternative as it best handles the issue of having duplicate logic. The internal parsing of the user inputs for suggestions differs from the Command Logic in that, Command Logic only has one level of parsing (parsing commands), whereas Suggestion Logic requires two levels (parsing commands and parsing prefixes). In order to ensure the same way of handling the same prefix in different commands (e.g. findtag t/ and edit 1 t/), methods are created to do so (e.g. SuggestionLogicManager#handleTagNameSuggestion). This keeps the code DRY and reduces repeats logic in the code.
Further abstractions can be made to this in the future as more Suggestion(s) added, by moving the suggestion handlers (SuggestionLogicManager#handleTagNameSuggestion) into a new Suggestion class (instead of an interface) that the specific XYZSuggestion(s) inherit from.
Aspect 2: Deciding on how to parse the user input
We have two options to parse the user input and find the prefixes and their values.
-
Alternative 1 (current choice): Use the existing
ArgumentTokenizerandArgumentMultimapto parse the user input-
Pros: The logic for separating the prefixes in
ArgumentTokenizerand storing them inArgumentMultimapis similar to what we need to parse our user input. By reusing the code, it prevents us from needing to rewrite code with duplicated logic elsewhere in our code base, which keeps our code DRY. -
Cons:
ArgumentTokenizerandArgumentMultimapis also used by the command logic subcomponent, by reusing this code in the suggestion logic subcomponent, it increases the coupling between the implementation of the two subcomponents which can result in new issues arising (aspects 3 and 4).
-
-
Alternative 2: Parse the input by using a separate piece of code (duplicated logic from the
ArgumentTokenizerandArgumentMultimap). Slight modifications will need to be made to the duplicated logic due to differences in implementation.-
Pros: Reduces the coupling between the two command and suggestion logic subcomponents. Although the logic behind the implementation will be similar to
ArgumentTokenizer, having it as a duplicate piece of code means that any changes will not affect and cause bugs in the other subcomponent. -
Cons: Having it duplicated logic might affect future development, especially when this duplicated logic needs to be modified, then the implementation for both pieces of code will have to be modified as well. If not documented properly, this could cause bugs if only one piece of code was modified.
-
Aspect 3: Data structure of Prefix
The original implementation of Prefix only stored the value of the prefix string (e.g. /t or /i), however since the implementation of the suggestion logic subcomponent uses ArgumentMultimap, it requires that the position of the Prefix in the user input string be known as well.
-
Alternative 1 (current choice): Store an additional field
positioninPrefix-
Pros: Since the prefix and its location are related, this keeps all the information pertaining to the prefix encapsulated in a single class, which helps with the modularity of the code.
-
Cons: The command logic subcomponent does not require the
positionfield inPrefix, which results in it being unused. This might be confusing for future developers. This also resulted in having another aspect to consider later on (aspect 4).
-
-
Alternative 2: Move the implementation and checks for the prefix position out of
Prefix-
Pros: This does not affect the code implemented in the Command logic subcomponent, and we will have less to fix.
-
Cons: Related pieces of code will be separated (i.e. since the position is stored separately, it is not properly encapsulated).
-
Aspect 4: Distinguishing each Prefix in ArgumentMultimap
The original hashcode used by Prefix only hashes the prefix string, as such, adding a position field will not make a difference since two same prefixes with different positions (e.g. /t … /t) will still hash to the same key. The previous implementation handles this by having the value in the HashMap within ArgumentMultimap store a List<String> which will append all values with the same prefix.
-
Alternative 1 (current choice): Set the hashcode of
Prefixto use both the prefix string and the position.-
Pros: The prefixes now hash differently if they have the same prefix string but different position, this allows us to have finer control needed for the Suggestion logic subcomponent when handling the prefixes in
ArgumentMultimap. -
Cons: The Command logic subcomponent does not make use of the
positionfield. As such, when attempting to extract out the values of eachPrefixat theParser, it cannot find the values as they are now hashed with thepositionas this is unknown to theParser(an indirect result of the coupling due to the chosen implementation in aspect 2).
-
-
Alternative 2: Use the original implementation
-
Pros: Code does not affect the Command logic subcomponent, which already takes up a significant portion of the code base, hence less changes are needed.
-
Cons: The code and logic are not be well encapsulated (for the
Prefix) and we will have repeated logic in the codebase.
-
We eventually chose Alternative 1 as it provides a better structure and encapsulation for our code overall. We also came up with a workaround for Alternative 1’s cons, by modifying the method ArgumentMultimap#getValue.
4.16. Command Highlight
The command highlight feature is to differentiate command word, index, prefix and values that user input in Command Line.
4.16.1. Current Implementation
The Command Highlight mechanism uses InlineCssTextArea class. It uses listener to detect the change in the commandTextArea and check if it contains command word, parameter, index or values and assign different colors correspondingly.
4.16.2. Design Consideration
Aspect: Implementation of command highlight manager.
-
Alternative 1 (current choice): Check the character in the command box and assign different colors based on precondition.
-
Pros: easy to implement by checking the prefix, index and command word.
-
Cons: due to the limitation of using the character '/' as part of the prefix, it may still have some corner cases that we cannot cover.
-
-
Alternative 2: Parse the user command simultaneously when user input command.
-
Pros: if user inputs wrong command format, it will highlight the color correspondingly. Hence, user can correct his input immediately.
-
Cons: difficult to implement.
-
5. Documentation
We use asciidoc for writing documentation. The following sections will provide common knowledge about how to use asciidoc for documentation.
| We chose asciidoc over Markdown because asciidoc, although a bit more complex than Markdown, provides more flexibility in formatting. |
5.1. Editing Documentation
See UsingGradle.adoc to learn how to render .adoc files locally to preview the end result of your edits.
Alternatively, you can download the AsciiDoc plugin for IntelliJ, which allows you to preview the changes you have made to your .adoc files in real-time.
5.2. Publishing Documentation
See UsingTravis.adoc to learn how to deploy GitHub Pages using Travis.
5.3. Converting Documentation to PDF format
We use Google Chrome for converting documentation to PDF format, as Chrome’s PDF engine preserves hyperlinks used in webpages.
Here are the steps to convert the project documentation files to PDF format.
-
Follow the instructions in UsingGradle.adoc to convert the AsciiDoc files in the
docs/directory to HTML format. -
Go to your generated HTML files in the
build/docsfolder, right click on them and selectOpen with→Google Chrome. -
Within Chrome, click on the
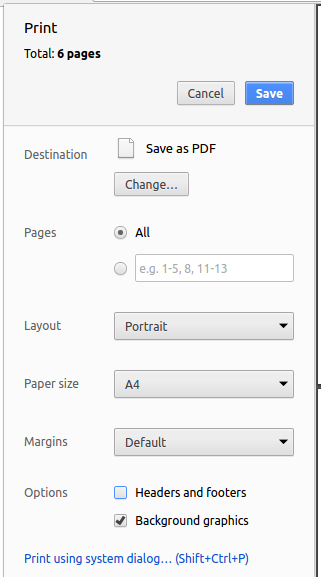
Printoption in Chrome’s menu. -
Set the destination to
Save as PDF, then clickSaveto save a copy of the file in PDF format. For best results, use the settings indicated in the screenshot below.
5.4. Site-wide Documentation Settings
The build.gradle file specifies some project-specific asciidoc attributes which affects how all documentation files within this project are rendered.
Attributes left unset in the build.gradle file will use their default value, if any.
|
| Attribute name | Description | Default value |
|---|---|---|
|
The name of the website. If set, the name will be displayed near the top of the page. |
not set |
|
URL to the site’s repository on GitHub. Setting this will add a "View on GitHub" link in the navigation bar. |
not set |
|
Define this attribute if the project is an official SE-EDU project. This will render the SE-EDU navigation bar at the top of the page, and add some SE-EDU-specific navigation items. |
not set |
5.5. Per-file Documentation Settings
Each .adoc file may also specify some file-specific asciidoc attributes which affects how the file is rendered.
Asciidoctor’s built-in attributes may be specified and used as well.
Attributes left unset in .adoc files will use their default value, if any.
|
| Attribute name | Description | Default value |
|---|---|---|
|
Site section that the document belongs to.
This will cause the associated item in the navigation bar to be highlighted.
One of: * Official SE-EDU projects only |
not set |
|
Set this attribute to remove the site navigation bar. |
not set |
5.6. Site Template
The files in docs/stylesheets are the CSS stylesheets of the site.
You can modify them to change some properties of the site’s design.
The files in docs/templates controls the rendering of .adoc files into HTML5.
These template files are written in a mixture of Ruby and Slim.
|
Modifying the template files in |
6. Testing
This section provides information related to testing, including three ways of testing, types of tests as well as troubleshooting testing.
6.1. Running Tests
There are three ways to run tests.
| The most reliable way to run tests is the 3rd one. The first two methods might fail some GUI tests due to platform/resolution-specific idiosyncrasies. |
Method 1: Using IntelliJ JUnit test runner
-
To run all tests, right-click on the
src/test/javafolder and chooseRun 'All Tests' -
To run a subset of tests, you can right-click on a test package, test class, or a test and choose
Run 'ABC'
Method 2: Using Gradle
-
Open a console and run the command
gradlew clean allTests(Mac/Linux:./gradlew clean allTests)
| See UsingGradle.adoc for more info on how to run tests using Gradle. |
Method 3: Using Gradle (headless)
Thanks to the TestFX library we use, our GUI tests can be run in the headless mode. In the headless mode, GUI tests do not show up on the screen. That means the developer can do other things on the Computer while the tests are running.
To run tests in headless mode, open a console and run the command gradlew clean headless allTests (Mac/Linux: ./gradlew clean headless allTests)
6.2. Types of tests
We have two types of tests:
-
GUI Tests - These are tests involving the GUI. They include,
-
System Tests that test the entire App by simulating user actions on the GUI. These are in the
systemtestspackage. -
Unit tests that test the individual components. These are in
seedu.saveit.uipackage.
-
-
Non-GUI Tests - These are tests not involving the GUI. They include,
-
Unit tests targeting the lowest level methods/classes.
e.g.seedu.saveit.commons.StringUtilTest -
Integration tests that are checking the integration of multiple code units (those code units are assumed to be working).
e.g.seedu.saveit.storage.StorageManagerTest -
Hybrids of unit and integration tests. These test are checking multiple code units as well as how the are connected together.
e.g.seedu.saveit.logic.LogicManagerTest
-
6.3. Troubleshooting Testing
Problem: HelpWindowTest fails with a NullPointerException.
-
Reason: One of its dependencies,
HelpWindow.htmlinsrc/main/resources/docsis missing. -
Solution: Execute Gradle task
processResources.
7. Dev Ops
This section provides a summary of useful development operations and brief information about them.
7.1. Build Automation
See UsingGradle.adoc to learn how to use Gradle for build automation.
7.2. Continuous Integration
We use Travis CI and AppVeyor to perform Continuous Integration on our projects. See UsingTravis.adoc and UsingAppVeyor.adoc for more details.
7.3. Coverage Reporting
We use Coveralls to track the code coverage of our projects. See UsingCoveralls.adoc for more details.
7.4. Documentation Previews
When a pull request has changes to asciidoc files, you can use Netlify to see a preview of how the HTML version of those asciidoc files will look like when the pull request is merged. See UsingNetlify.adoc for more details.
7.5. Making a Release
Here are the steps to create a new release.
-
Update the version number in
MainApp.java. -
Generate a JAR file using Gradle.
-
Tag the repo with the version number. e.g.
v0.1 -
Create a new release using GitHub and upload the JAR file you created.
7.6. Managing Dependencies
A project often depends on third-party libraries. For example, SaveIt depends on the Jackson library for XML parsing. Managing these dependencies can be automated using Gradle. For example, Gradle can download the dependencies automatically, which is better than these alternatives.
a. Include those libraries in the repo (this bloats the repo size)
b. Require developers to download those libraries manually (this creates extra work for developers)
Appendix A: Suggested Programming Tasks to Get Started
Suggested path for new programmers:
-
First, add small local-impact (i.e. the impact of the change does not go beyond the component) enhancements to one component at a time. Some suggestions are given in Section A.1, “Improving each component”.
-
Next, add a feature that touches multiple components to learn how to implement an end-to-end feature across all components. Section A.2, “Creating a new command:
remark” explains how to go about adding such a feature.
A.1. Improving each component
Each individual exercise in this section is component-based (i.e. you will not need to modify the other components to get it to work).
Logic component
Scenario: You are in charge of logic. During dog-fooding, your team realize that it is troublesome for the user to type the whole command in order to execute a command. Your team devise some strategies to help cut down the amount of typing necessary, and one of the suggestions was to implement aliases for the command words. Your job is to implement such aliases.
Do take a look at Section 3.3, “Logic component” before attempting to modify the Logic component.
|
-
Add a shorthand equivalent alias for each of the individual commands. For example, besides typing
clear, the user can also typecto remove all issues in the list.
Model component
Scenario: You are in charge of model. One day, the logic-in-charge approaches you for help. He wants to implement a command such that the user is able to remove a particular tag from everyone in the SaveIt, but the model API does not support such a functionality at the moment. Your job is to implement an API method, so that your teammate can use your API to implement his command.
Do take a look at Section 3.4, “Model component” before attempting to modify the Model component.
|
-
Add a
removeTag(Tag)method. The specified tag will be removed from everyone in the SaveIt.
Ui component
Scenario: You are in charge of ui. During a beta testing session, your team is observing how the users use your SaveIt application. You realize that one of the users occasionally tries to delete non-existent tags from a contact, because the tags all look the same visually, and the user got confused. Another user made a typing mistake in his command, but did not realize he had done so because the error message wasn’t prominent enough. A third user keeps scrolling down the list, because he keeps forgetting the index of the last statement in the list. Your job is to implement improvements to the UI to solve all these problems.
Do take a look at Section 3.2, “UI component” before attempting to modify the UI component.
|
-
Use different colors for different tags inside statement cards. For example,
friendstags can be all in brown, andcolleaguestags can be all in yellow.Before

After
-
Modify
NewResultAvailableEventsuch thatResultDisplaycan show a different style on error (currently it shows the same regardless of errors).Before
After
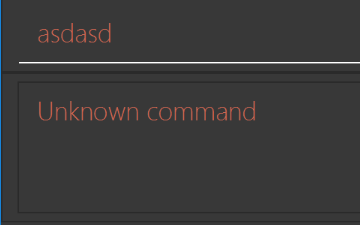
-
Modify the
StatusBarFooterto show the total number of issues in the SaveIt.Before

After

Storage component
Scenario: You are in charge of storage. For your next project milestone, your team plans to implement a new feature of saving the SaveIt to the cloud. However, the current implementation of the application constantly saves the SaveIt after the execution of each command, which is not ideal if the user is working on limited internet connection. Your team decided that the application should instead save the changes to a temporary local backup file first, and only upload to the cloud after the user closes the application. Your job is to implement a backup API for the SaveIt storage.
Do take a look at Section 3.5, “Storage component” before attempting to modify the Storage component.
|
-
Add a new method
backupSaveIt(ReadOnlySaveIt), so that the SaveIt can be saved in a fixed temporary location.
A.2. Creating a new command: remark
By creating this command, you will get a chance to learn how to implement a feature end-to-end, touching all major components of the app.
Scenario: You are a software maintainer for saveit, as the former developer team has moved on to new projects. The current users of your application have a list of new feature requests that they hope the software will eventually have. The most popular request is to allow adding additional comments/notes about a particular contact, by providing a flexible remark field for each contact, rather than relying on tags alone. After designing the specification for the remark command, you are convinced that this feature is worth implementing. Your job is to implement the remark command.
Edits the remark for an issue specified in the INDEX.
Format: edit Index r/[REMARK] s/[SOLUTION]
Examples:
-
remark 1 r/Likes to drink coffee.
Edits the remark for the first statement toLikes to drink coffee. -
remark 1 r/
Removes the remark for the first statement.
A.2.1. Step-by-step Instructions
[Step 1] Logic: Teach the app to accept 'remark' which does nothing
Let’s start by teaching the application how to parse a remark command. We will add the logic of remark later.
Main:
-
Add a
RemarkCommandthat extendsCommand. Upon execution, it should just throw anException. -
Modify
SaveItParserto accept aRemarkCommand.
Tests:
-
Add
RemarkCommandTestthat tests thatexecute()throws an Exception. -
Add new test method to
SaveItParserTest, which tests that typing "remark" returns an instance ofRemarkCommand.
[Step 2] Logic: Teach the app to accept 'remark' arguments
Let’s teach the application to parse arguments that our remark command will accept. E.g. 1 r/Likes to drink coffee.
Main:
-
Modify
RemarkCommandto take in anIndexandStringand print those two parameters as the error message. -
Add
RemarkCommandParserthat knows how to parse two arguments, one index and one with prefix 'r/'. -
Modify
SaveItParserto use the newly implementedRemarkCommandParser.
Tests:
-
Modify
RemarkCommandTestto test theRemarkCommand#equals()method. -
Add
RemarkCommandParserTestthat tests different boundary values forRemarkCommandParser. -
Modify
SaveItParserTestto test that the correct command is generated according to the user input.
[Step 3] Ui: Add a placeholder for remark in IssueCard
Let’s add a placeholder on all our IssueCard s to display a remark for each statement later.
Main:
-
Add a
Labelwith any random text insidePersonListCard.fxml. -
Add FXML annotation in
IssueCardto tie the variable to the actual label.
Tests:
-
Modify
IssueCardHandleso that future tests can read the contents of the remark label.
[Step 4] Model: Add Remark class
We have to properly encapsulate the remark in our Issue class. Instead of just using a String, let’s follow the conventional class structure that the codebase already uses by adding a Remark class.
Main:
-
Add
Remarkto model component (you can copy fromRemark, remove the regex and change the names accordingly). -
Modify
RemarkCommandto now take in aRemarkinstead of aString.
Tests:
-
Add test for
Remark, to test theRemark#equals()method.
[Step 5] Model: Modify Issue to support a Remark field
Now we have the Remark class, we need to actually use it inside Issue.
Main:
-
Add
getRemark()inIssue. -
You may assume that the user will not be able to use the
addandeditcommands to modify the remarks field (i.e. the statement will be created without a remark). -
Modify
SampleDataUtilto add remarks for the sample data (delete yoursaveit.xmlso that the application will load the sample data when you launch it.)
[Step 6] Storage: Add Remark field to XmlAdaptedIssue class
We now have Remark s for Issue s, but they will be gone when we exit the application. Let’s modify XmlAdaptedIssue to include a Remark field so that it will be saved.
Main:
-
Add a new Xml field for
Remark.
Tests:
-
Fix
invalidAndValidIssueSaveIt.xml,typicalIssuesSaveIt.xml,validSaveIt.xmletc., such that the XML tests will not fail due to a missing<remark>element.
[Step 6b] Test: Add withRemark() for IssueBuilder
Since Issue can now have a Remark, we should add a helper method to IssueBuilder, so that users are able to create remarks when building a Issue.
Tests:
-
Add a new method
withRemark()forIssueBuilder. This method will create a newRemarkfor the statement that it is currently building. -
Try and use the method on any sample
IssueinTypicalPersons.
[Step 7] Ui: Connect Remark field to IssueCard
Our remark label in IssueCard is still a placeholder. Let’s bring it to life by binding it with the actual remark field.
Main:
-
Modify
IssueCard's constructor to bind theRemarkfield to theIssue's remark.
Tests:
-
Modify
GuiTestAssert#assertCardDisplaysIssue(…)so that it will compare the now-functioning remark label.
[Step 8] Logic: Implement RemarkCommand#execute() logic
We now have everything set up… but we still can’t modify the remarks. Let’s finish it up by adding in actual logic for our remark command.
Main:
-
Replace the logic in
RemarkCommand#execute()(that currently just throws anException), with the actual logic to modify the remarks of an issue.
Tests:
-
Update
RemarkCommandTestto test that theexecute()logic works.
A.2.2. Full Solution
See this PR for the step-by-step email.
Appendix B: Product Scope
Target user profile:
-
has a need to manage previous technical issues
-
prefer desktop apps over other types
-
can type fast
-
prefers typing over mouse input
-
is reasonably comfortable using CLI apps
Value proposition: Manage the technical issues for future reference
Appendix C: User Stories
Priorities: High (must have) - * * *, Medium (nice to have) - * *, Low (unlikely to have) - *
| Priority | As a … | I want to … | So that I can… |
|---|---|---|---|
|
programmer |
record the statement and email |
review it when I encounter it again |
|
programmer using multiple programming languages |
search issues of different language easily |
fix my code easily |
|
learner of programming |
record the technical details |
refer to it in the future |
|
CS Professor |
record the common mistakes that students tend to make |
reinforce or spend more time covering those areas |
|
team member of a SWE team |
share solutions which I have found previously for each bug I encountered with my team |
help my team by reducing their time spent on debugging |
|
programmer |
add remark for the issues |
have better understanding of the statement |
|
a CS student |
note common mistakes among my classmates |
learn from their mistakes and avoid the those mistakes |
|
a programmer dealing with many programs at the same time |
search the issue based on the tag or key words |
So that i can find the issue easily |
|
a programmer encounter various issues while coding |
add the tag for each statement |
collect same tag |
|
a CS student who aims to improve technical skills |
store the way I solved certain technical issue |
review it and see if there is a better solution in the future |
|
a busy programmer dealing with a big project |
highlight the certain part of the page |
See the most important part of the solution |
|
a CS student who are learning new techniques |
delete the statement after I got familiar with that statement |
pay more attention to those I am not familiar with |
|
a CS student |
collect all the mistakes i have made during daily coding practice |
revise them before exam |
|
developer maintaining an open source project |
allow external developers who might be working on PRs of the project to have access to the mistakes or bugs encountered during development |
help them with any bugs that they encountered |
|
normal user |
have a autocomplete command |
type faster and do not needd to memorise command format |
|
normal user |
have a autosuggestion tag |
type faster |
|
normal user |
have different color for different parameters in each command |
distinguish different fields I entered easily |
{More to be added}
Appendix D: Use Cases
(For all use cases below, the System is the SaveIt and the Actor is the user, unless specified otherwise)
Use case: Add issue
MSS
-
User requests to add a new issue
-
SaveIt adds the issue to its storage
-
The ‘Success’ message is shown on the screen.
Use case ends.
Extensions
-
1a. The command entered is invalid.
-
1a1. The 'Invalid Command' message shown on the screen.
Use case resumes at step 1.
-
Use case: Add solution
MSS
-
User requests to list issues
-
SaveIt shows a list of issues
-
User selects a specific issue in the list
-
SaveIt shows the solution lists of the selected issue
-
User requests to add a new solution to this issue
-
SaveIt adds the solution
-
The 'Success' message is shown on the screen.
Use case ends.
Extensions
-
2a. The list is empty.
Use case ends.
-
3a. The given index is invalid.
-
3a1. The 'Invalid Index' message shown on the screen.
Use case resumes at step 2.
-
-
5a. The command entered is invalid.
-
5a1. The 'Invalid Command' message shown on the screen.
Use case resumes at step 4.
-
-
5b. None of the optional field is provided
-
5b1. SaveIt shows an error message
Use case resumes at step 4.
-
Use case: Select issue
MSS
-
User requests to list issues
-
SaveIt shows a list of issues
-
User requests to select a specific issue in the list
-
SaveIt selects the issue
Use case ends.
Extensions
-
2a. The list is empty.
Use case ends.
-
3a. The given index is invalid.
-
3a1. The 'Invalid Index' message shown on the screen.
Use case resumes at step 2.
-
Use case: Edit statement and description
MSS
-
User requests to list issues
-
SaveIt shows a list of issues
-
User requests to edit the issue statement and description of a issue
-
SaveIt updates the statement and description
-
The ‘Success’ message is shown on the screen.
Use case ends.
Extensions
-
2a. The list is empty.
Use case ends.
-
3a. The given index is invalid.
-
3a1. The 'Invalid Index' message shown on the screen.
Use case resumes at step 2.
-
-
3b. None of the optional fields is provided.
-
3b1. SaveIt shows an error message.
Use case resumes at step 2.
-
Use case: Edit solution
MSS
-
User requests to list issues
-
SaveIt shows a list of issues
-
User selects a specific issue in the list
-
SaveIt shows the solution lists of the selected issue
-
User requests to edit a specific solution in the selected issue
-
SaveIt updates the solution
-
The ‘Success’ message is shown on the screen
Use case ends.
Extensions
-
2a. The list is empty.
Use case ends.
-
3a. The given index is invalid.
-
3a1. The 'Invalid Index' message shown on the screen.
Use case resumes at step 2.
-
-
5a. The given index is invalid.
-
5a1. The 'Invalid Index' message shown on the screen.
Use case resumes at step 4.
-
-
5b. None of the optional fields is provided
-
5b1. SaveIt shows an error message.
Use case resumes at step 4.
-
Use case: Delete issue
MSS
-
User requests to list issues
-
SaveIt shows a list of issues
-
User requests to delete a specific issue in the list
-
SaveIt deletes the issue
-
The "Success" message is shown on the screen.
Use case ends.
Extensions
-
2a. The list is empty.
Use case ends.
-
3a. The given index is invalid.
-
3a1. The 'Invalid Index' message shown on the screen.
Use case resumes at step 2.
-
{More to be added}
Appendix E: Non Functional Requirements
-
Should work on any mainstream OS as long as it has Java
9or higher installed. -
Should be able to hold up to 1000 issues without a noticeable sluggishness in performance for typical usage.
-
A user with above average typing speed for regular English text (i.e. not code, not system admin commands) should be able to accomplish most of the tasks faster using commands than using the mouse.
-
Should work with or without internet connection.
-
The data used should be stored locally.
{More to be added}
Appendix G: Product Survey
Product Name
Author: …
Pros:
-
…
-
…
Cons:
-
…
-
…
Appendix H: Instructions for Manual Testing
Given below are instructions to test the app manually.
| These instructions only provide a starting point for testers to work on; testers are expected to do more exploratory testing. |
H.1. Launch and Shutdown
-
Initial launch
-
Download the jar file and copy into an empty folder
-
Double-click the jar file
Expected: Shows the GUI with a set of sample contacts. The window size may not be optimum.
-
-
Saving window preferences
-
Resize the window to an optimum size. Move the window to a different location. Close the window.
-
Re-launch the app by double-clicking the jar file.
Expected: The most recent window size and location is retained.
-
H.2. Adding an issue
-
Adding an issue in root directory
-
Prerequisites: User is in root directory
-
Test case:
add i/problem d/description t/UI
Expected: A new issue with statement and description is added, tagged with UI. -
Test case:
add t/UI d/description d/newdescription i/problem
Expected: A new issue with statement and newdescription is added, tagged with UI. -
Test case:
add i/proπblem d/description
Expected: No issue is added. Error details shown in the status message. Status bar remains the same. -
Test case:
add s/www.example.com r/remark
Expected: No issue is added. Error details shown in the status message. Status bar remains the same. -
Other incorrect add commands to try:
add i/problem,add i/problem s/link{give more}
Expected: Similar to previous.
-
{ more test cases … }
H.3. Editing an issue
-
Editing an issue in home directory
-
Prerequisites: User is in home directory
-
Test case:
edit 1 i/problem
Expected: First issue is edited. Its new issue statement is problem. -
Test case:
edit 1 d/description d/newdescription
Expected: First issue is edited. Its new description is newdescription. -
Test case:
edit 1 i/proπblem
Expected: No issue is edited. Error details shown in the status message. Status bar remains the same. -
Test case:
edit 1 s/www.example.com r/remark
Expected: No issue is edited. Error details shown in the status message. Status bar remains the same. -
Other incorrect add commands to try:
edit i/problem s/link,edit x i/problem(where x is larger than the list size) {give more}
Expected: Similar to previous.
-
{ more test cases … }
H.4. Deleting an issue
-
Deleting an issue while all issues are listed
-
Prerequisites: List all issues using the
listcommand. Multiple issues in the list. -
Test case:
delete 1
Expected: First contact is deleted from the list. Details of the deleted contact shown in the status message. Timestamp in the status bar is updated. -
Test case:
delete 0
Expected: No statement is deleted. Error details shown in the status message. Status bar remains the same. -
Test case:
delete a
Expected: No statement is deleted. Error details shown in the status message. Status bar remains the same. -
Other incorrect delete commands to try:
delete,delete x(where x is larger than the list size) {give more}
Expected: Similar to previous.
-
{ more test cases … }
H.5. Sorting an issue list
-
Sorting the issue list in root directory
-
Prerequisites: User is in root directory
-
Test case:
sort
Expected: Issues are sorted by adding order. -
Test case:
sort freq
Expected: Issues are sorted by search frequency. -
Test case:
sort random
Expected: The invalid command error it shown in the status message. The issue list remains the same. -
Test case:
sort tag random
Expected: The invalid command error it shown in the status message. The issue list remains the same.
-
H.6. Saving data
-
Dealing with missing/corrupted data files
-
{explain how to simulate a missing/corrupted file and the expected behavior}
-
{ more test cases … }